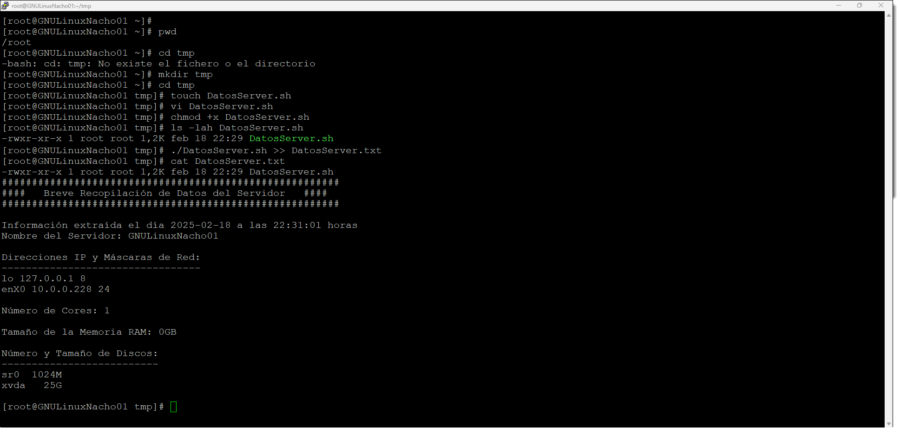
Comment effectuer une collecte de données de base pour les migrations GNU/Linux ?
Comment effectuer une collecte de données de base pour les migrations GNU/Linux ?
Écrit par
Catégories
Migrations
Serveurs