Revisa cómo integrar Almacenamiento de Objetos de Jotelulu con un cliente S3 en dos pasos: recopila la información y configura tu servicio.
Almacenamiento de Objetos es un sistema de almacenamiento que está pensado para guardar grandes volúmenes de datos de aplicaciones (de archivado, backup, IoT, AI, DevOps…) a través de una API Web. El presente tutorial explica la forma de integrar/conectar el bucket o repositorio con esas aplicaciones de forma estándar a través de la API.
¿Cómo integrar Almacenamiento de Objetos con un cliente S3?
Pre-requisitos o pre-configuración:
Para completar de forma satisfactoria este tutorial y poder dar de alta un bucket de Almacenamiento de Objetos se necesitará:
- Por un lado, estar dado de alta en la Plataforma Jotelulu y haber accedido a la misma con su nombre y contraseña a través del proceso de Log-in.
- Haber dado de alta una suscripción de Almacenamiento de Objetos previamente.
- Tener una aplicación a la que conectar el repositorio a través de la API Web.
Paso 1. Recopilar la información de Almacenamiento de Objetos para la integración
El proceso comienza una vez el usuario se encuentra en el Dashboard Inicial y accede al repositorio (1) a través de la Card con el mismo nombre.
Una vez en la sección resumen del repositorio seleccionado, se procederá a recopilar la información necesaria para llevar a cabo la integración. En líneas generales la integración con una API web necesita de:
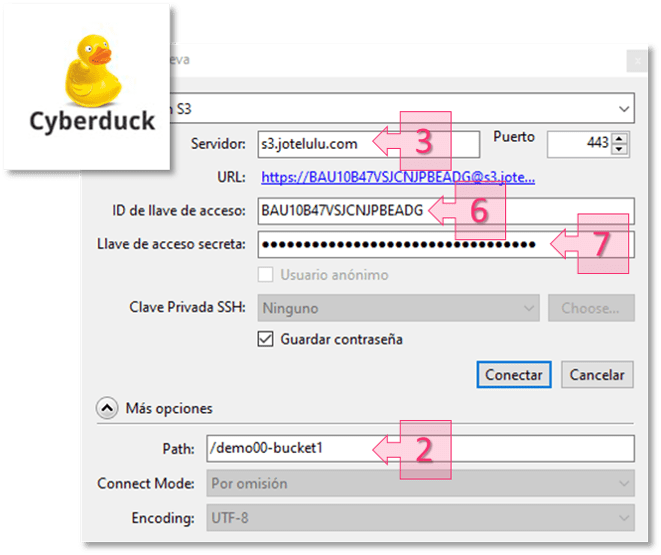
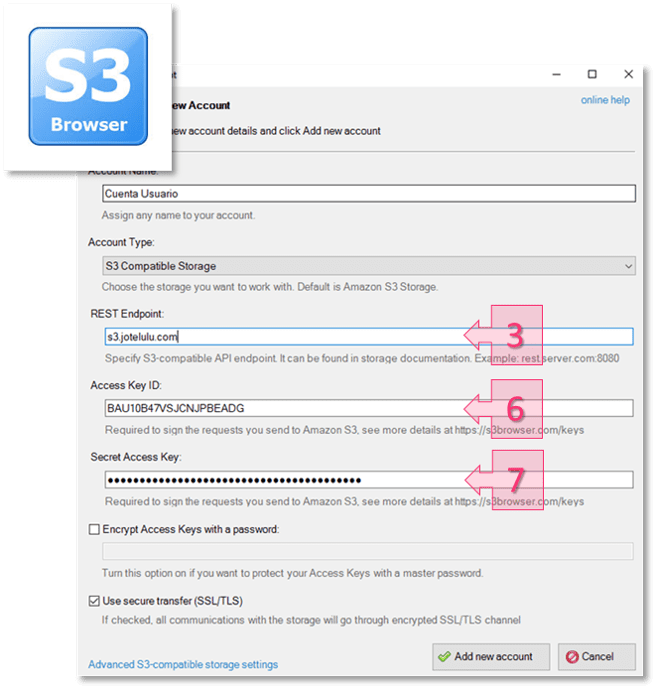
- Acceso al bucket (URL web) / Servidor.
- Un Path que corresponde con el nombre del bucket o repositorio.
- Un Access Key (conocida en castellano como ID de llave de acceso)
- Un Secret Key(traducida muchas veces como Llave de acceso secreta).
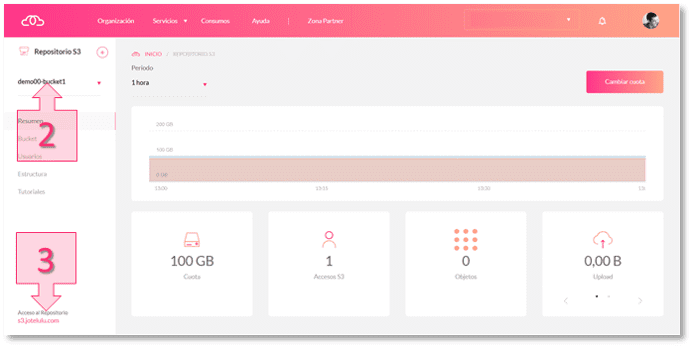
El nombre del bucket o repositorio está disponible en la parte superior izquierda de la sección resumen (2) [en este ejemplo: «demo00-bucket1»] mientras que la URL de acceso al repositorio está ubicada en la parte inferior izquierda (3) [en este ejemplo: «s3.jotelulu.com»].
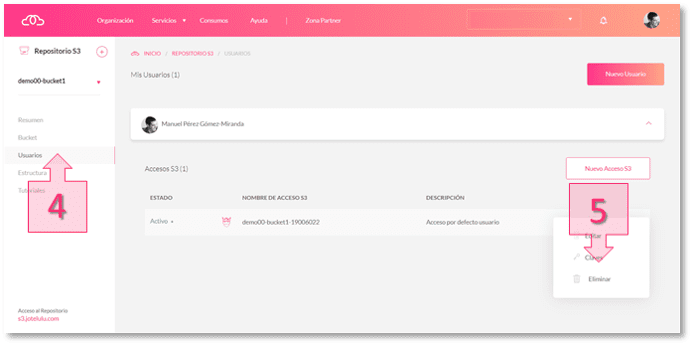
Para localizar el Access Key y el Secret Key del repositorio será necesario acceder a la sub-sección usuarios (4) y pinchar sobre la opción Claves (5) disponible en el menú conceptual (…) asociado al acceso del usuario.
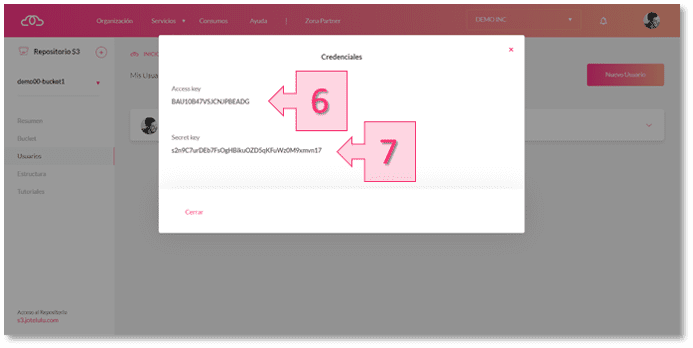
Una vez seleccionada la opción “Claves”, la plataforma facilitará el Access Key (6) y el Secret Key (7) necesarios para completar la información que necesitaremos para la integración con el cliente S3.
Paso 2. Configura el cliente S3 para integrarlo con tu bucket.
A la hora de configurar un cliente S3, como por ejemplo, CyberDuck, es importante diferenciar entre dos tipos de usuarios. Por un lado, está el OWNER que es el propietario o creador de la cuenta y el resto de los usuarios que tienen acceso porque se le ha configurado el acceso.
El OWNER, al ser el propietario de la cuenta tiene acceso directo al recurso, y no necesita configurar nada, simplemente accede de manera automática. El resto de los usuarios, tendrán que rellenar el campo de “path” a la que quiere acceder, ya que no tiene acceso directo al recurso y no es redirigido.
Una vez toda la información ha sido recopilada, procederemos a introducir los datos en el cliente S3.
- Ejemplo del proceso integración con CyberDuck.
- Ejemplo del proceso integración con S3 Browser.
Conclusiones y posibles próximos pasos:
La integración de Almacenamiento de Objetos con un cliente S3 simplemente necesita de la recopilación de información dentro de la plataforma y su introducción en el cliente S3 tal y como se muestra en esta guía.
Es posible que tras leer este tutorial necesites entender conceptos más básicos sobre Almacenamiento de Objetos, si fuera así por favor consulta:
- Guía Rápida de Almacenamiento de Objetos (conceptos básicos del servicio).
- Cómo dar de alta una suscripción de Almacenamiento de Objetos.
O quizás, simplemente quieras ampliar información y saber que otras funcionalidades se pueden activar desde la plataforma. Entonces quizás esto te interese:
- Cómo asignar permisos/accesos en Almacenamiento de Objetos (próximamente).
Sea como fuere, esperamos que el presente tutorial te haya ayudado a entender un poco más el servicio y puedas llevar a cabo tu integración sin problemas. Muchas gracias.