Descubre cómo migrar una máquina GNU/Linux de Amazon Web Services (AWS) a tu infraestructura de Jotelulu de manera sencilla.
En ocasiones, podemos encontrarnos con que queremos migrar máquinas de nuestra infraestructura anterior para unificar y centralizarlo todo, y por ello necesitamos extraer el servidor de su localización anterior, que en este caso es Amazon Web Services (AWS) y llevarlo a otra localización, en este caso a Jotelulu.
En este pequeño tutorial, vamos a describir como hacer este proceso de manera completamente guiada.
¿Cómo migrar un servidor GNU/Linux desde AWS a Jotelulu?
Pre-requisitos o pre-configuración:
Para completar de forma satisfactoria este tutorial y poder importar un servidor de Amazon Web Services (AWS) como un servidor dentro de nuestra suscripción de servidores de Jotelulu será necesario:
- Por un lado, estar dado de alta en la Plataforma y estar registrado en la misma tras hacer login.
- Tener permisos de administrador de compañía o de alguna suscripción de servidores.
- Tener una suscripción de AWS con un mínimo de un servidor a exportar.
Limitaciones:
- AWS no permite exportar imágenes que contengan software de terceros proporcionado por AWS. Por tanto, no se puede exportar Windows, SQL Server, ni imágenes creadas a partir de una imagen de AWS Marketplace.
- No se pueden exportar imágenes con instantáneas de EBS cifradas en la asignación de dispositivos de bloques.
- Solo puede exportar volúmenes de datos de EBS especificados en la asignación de dispositivos de bloques.
- No se pueden exportar volúmenes de EBS asociados después del lanzamiento de la instancia.
- No se pueden exportar imágenes desde Amazon EC2 si la ha compartido desde otra cuenta AWS.
- No pueden lanzarse varias tareas de exportación de imágenes al mismo tiempo en la misma AIM.
- No puede tener más de 5 tareas de conversión simultaneas por región, pero puede cambiarse hasta 20 de manera manual.
- No pueden exportarse máquinas virtuales con volúmenes superiores a 1 TB.
Paso 0. Preparación de la máquina GNU/Linux
Antes de empezar el proceso de migración de AWS a Jotelulu, se debe hacer una preparación previa del servidor para su migración, repasando que se cumplen los siguientes puntos:
- Se debe habilitar SSH (Secure Shell o Shell seguro) para permitir el acceso remoto.
- Se debe permitir el acceso de sesiones remotas de SSH a través de cualquier firewall existente en la máquina (ejemplo de iptables).
- Se debe preparar un usuario adicional (no root) para trabajar con él en sesiones SSH (por ejemplo, crear el usuario jotelulu).
- Se debe comprobar que la máquina virtual utiliza GRUB (Grand Unified Bootloader) (GRUB Legacy) o GRUB 2 como gestor de arranque.
- Se debe comprobar que el servidor GNU/Linux usa uno de los siguientes sistemas de archivos raíz EXT2, EXT3, EXT4, Btrfs, JFS, o XFS para evitar problemas.
Paso 1. Preparación de la línea de comandos de AWS en el sistema desde el que se va a lanzar la migración
Una vez preparada la máquina virtual que se quiere extraer, lo primero que se tiene que hacer es preparar el sistema desde el que vamos a lanzar la operativa (normalmente nuestro equipo de trabajo local) para poder lanzar los comandos necesarios para la exportación del servidor.
Lo primero será poder ejecutar comandos de “aws cli” o lo que es lo mismo, poder lanzar órdenes del intérprete de la línea de comandos de AWS.
Para ello, se deberá ir a la página de “interfaz de línea de comandos de AWS” y en caso de estar trabajando desde un cliente Windows, descargar la aplicación para sistema de 32bits o de 64 bits.
Mientras que si estamos trabajando desde una máquina GNU/Linux deberemos descargar e instalar los paquetes de Python y Pip.
En el caso de este tutorial, vamos a suponer que el lector dispone de un sistema Microsoft Windows y seguiremos los procedimientos con dicho sistema.
En el caso de Windows, una vez descargada la aplicación, la lanzaremos con una cuenta con privilegios de administración del sistema y seguiremos el proceso de instalación que es básicamente un “siguiente-siguiente”, motivo por el que no se incluye aquí, para no hacer el tutorial más largo.
Una vez instalado, se debería añadir la aplicación al Path de Windows para poder usar los comandos desde cualquier ruta del sistema.
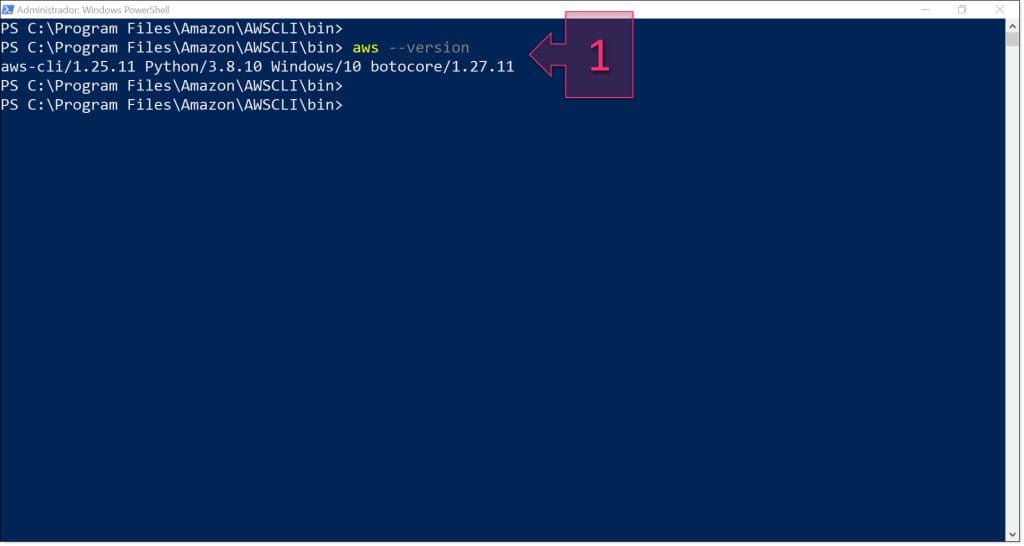
Para comprobar que todo ha ido bien y que se puede hacer uso de los comandos de AWS CLI desde la línea de comandos, lanzaremos el comando “aws –versión” (1), que nos muestra la versión del programa que se ha instalado en el sistema.
Cuando tenemos claro que todo funciona correctamente, es hora de pasar al siguiente paso de la operativa.
Paso 2. Preparación del S3 de AWS
El siguiente paso será desplegar un S3 dentro de AWS que tiene que estar en la misma región que la máquina virtual que se quiere extraer. Si por ejemplo se tiene el servidor hospedado en Irlanda (eu-west-1), el S3 debe desplegarse también en Irlanda (eu-west-1).
El proceso de despliegue de dicho S3 puede realizarse de varias maneras, como por ejemplo desde “aws cli”, desde Terraform o desde consola web. En nuestro caso vamos a ver cómo hacerlo desde la consola web ya que es el método más sencillo.
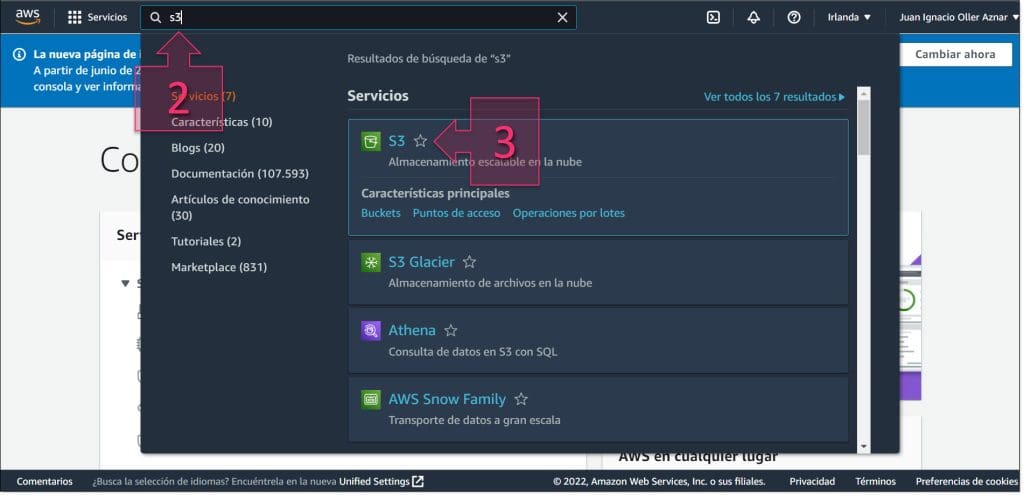
En la parte superior de la consola de AWS se puede encontrar la barra de búsqueda, donde se debe escribir “S3” (2) y entre las opciones que se muestran, se debe hacer clic en “S3” (3).
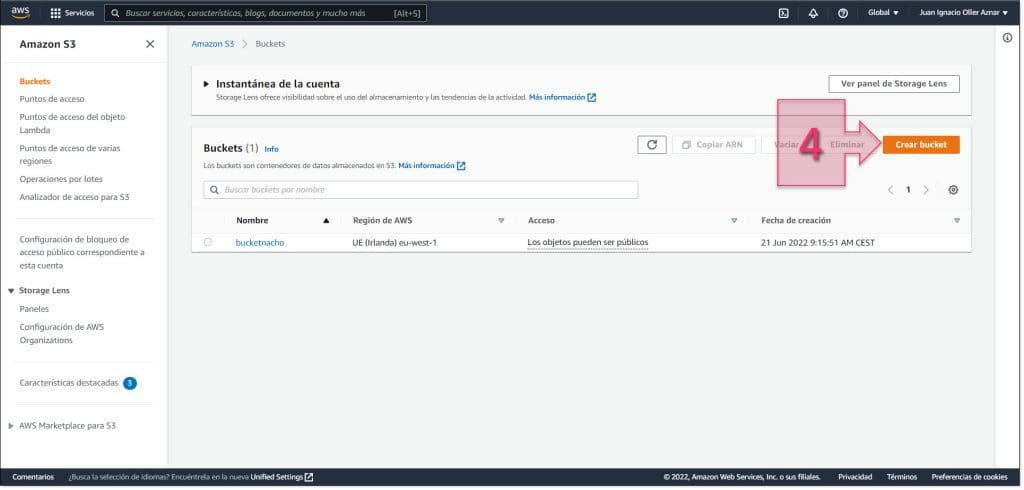
Una vez en la consola de S3, se debe ir a la parte superior derecha y hacer clic en “Crear Bucket” (4) para lanzar la creación del nuevo bucket de S3.
En la ventana “Crear bucket” se debe escribir el nombre que se quiere dar en “Nombre de bucket” (5), además se debe validar que se va a desplegar en la “Region de AWS” (6) que se quiere utilizar, que tal como hemos dicho antes, debe ser la misma que la máquina virtual a exportar.
Además, en Propiedades de objetos se deberá marcar “ACL habilitadas” (7)
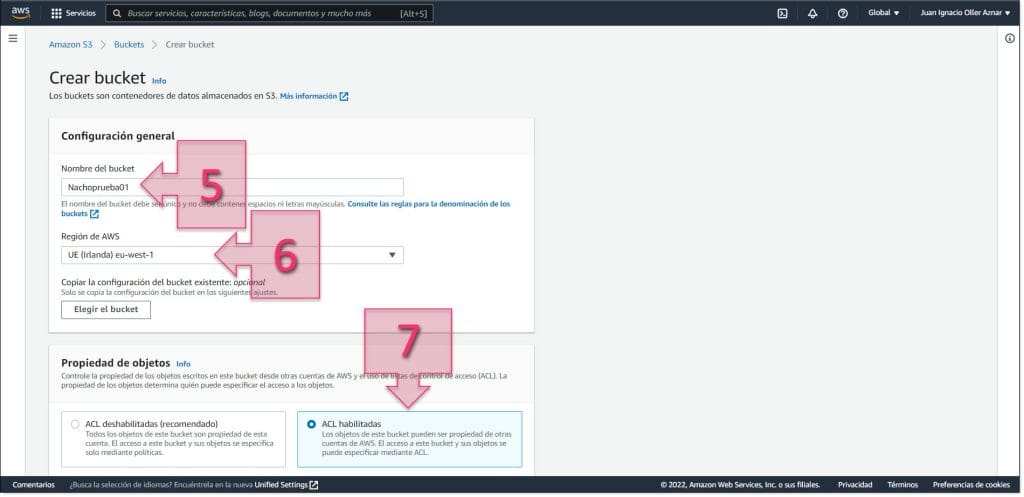
En la “configuración de bloqueo de acceso público para este bucket” se debe desmarcar el checkbox en “bloquear todo el acceso público” y aceptar el aviso sobre el cambio de configuración (8).
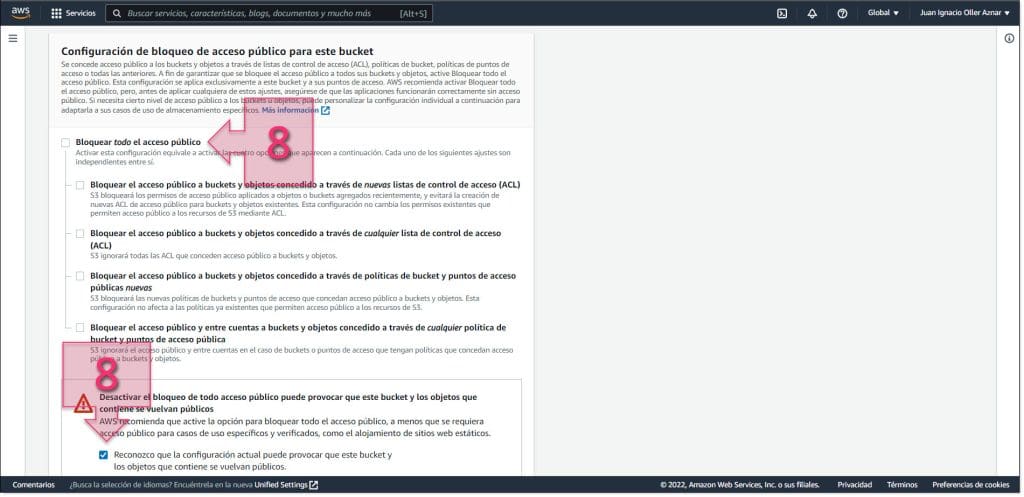
El resto de la configuración queda configurado de la forma en que viene por defecto, y simplemente habrá que hacer clic en “Crear Bucket” (9).
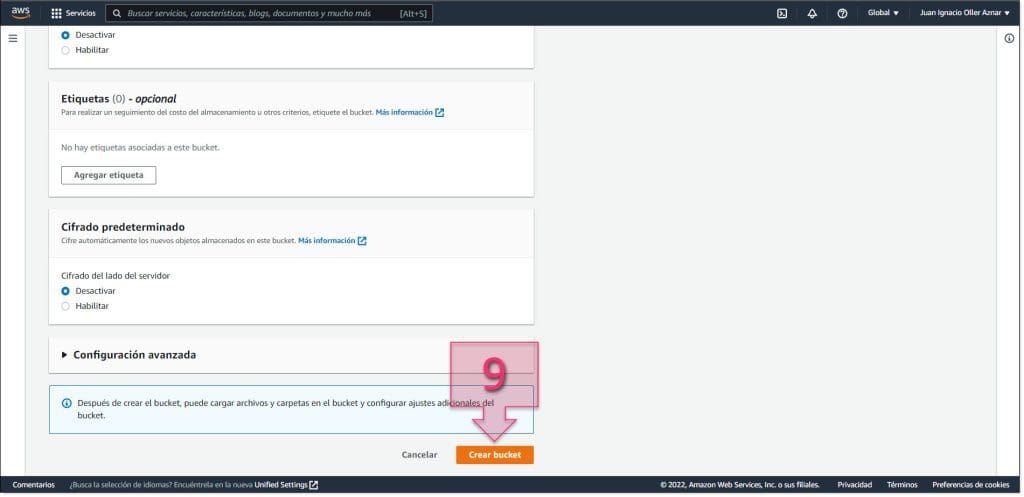
En este punto habrá que esperar un momento mientras se despliega el nuevo S3, y una vez desplegado se deberá acceder al mismo para su configuración final. Para ello se deberá hacer clic en el nombre (10).
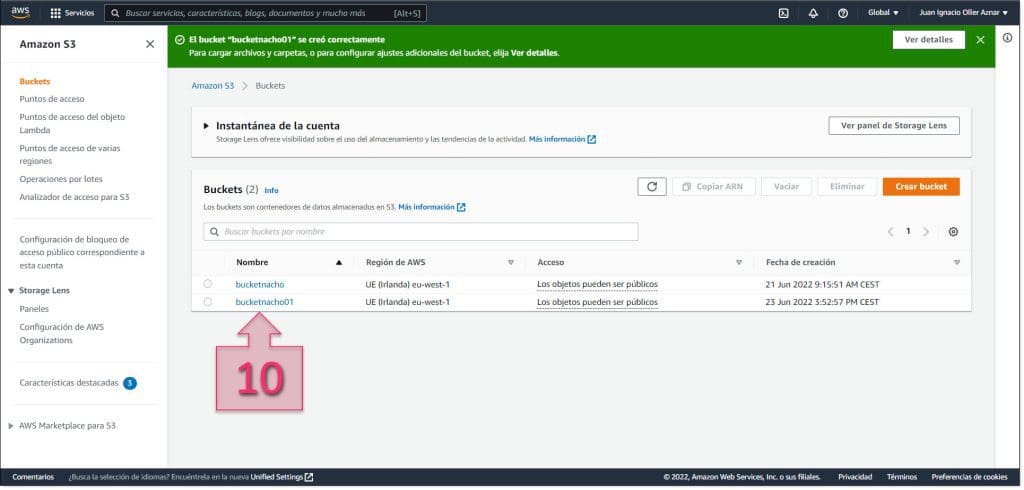
El siguiente punto para configurar dentro del nuevo bucket son los permisos de acceso, por lo que se deberá hacer clic en la pestaña “Permisos” (11).
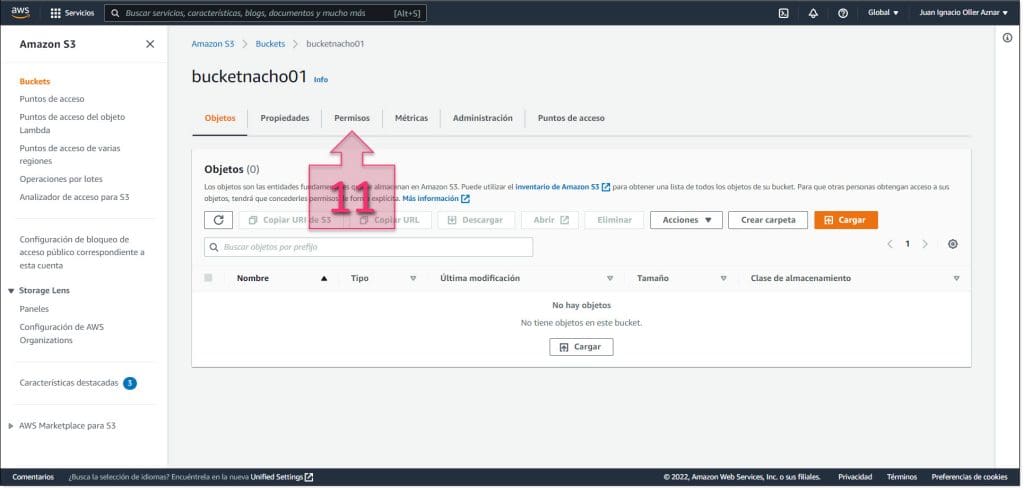
Una vez situados en la pestaña de “Permisos” se debe ir a “Lista de control de acceso (ACL)” y hacer clic en “Editar” (12).
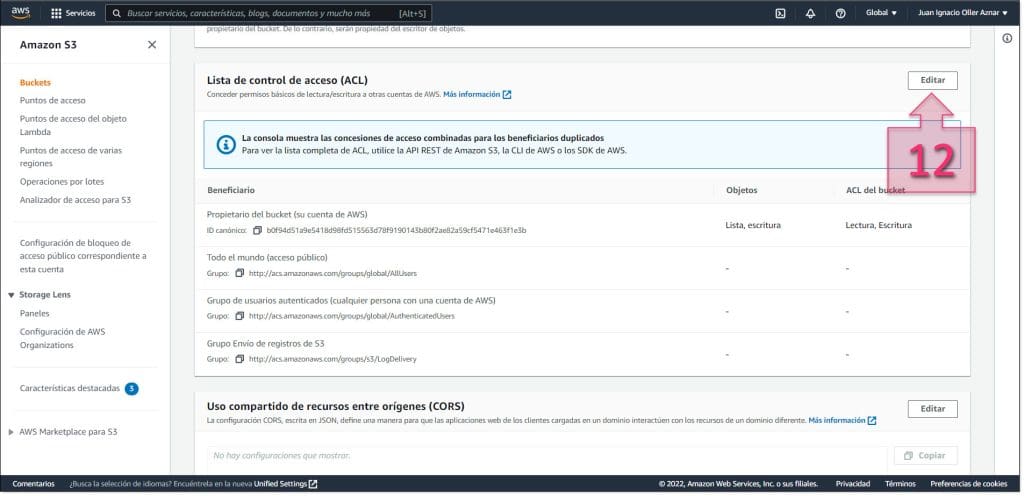
Una vez dentro de las ACL, se debe ir a la parte inferior y hacer clic en “Agregar beneficiario” (13). En este momento se deberá introducir la cadena que ponemos a continuación “6e81c4c52a37a7f59e103625162ed97bcd0e646593adb107d21310d093151518”, que sirve para la zona de España, y marcar los checkbox de escritura y lectura (14).
Una vez agregado, se debe hacer clic en “Guardar cambios” (15).
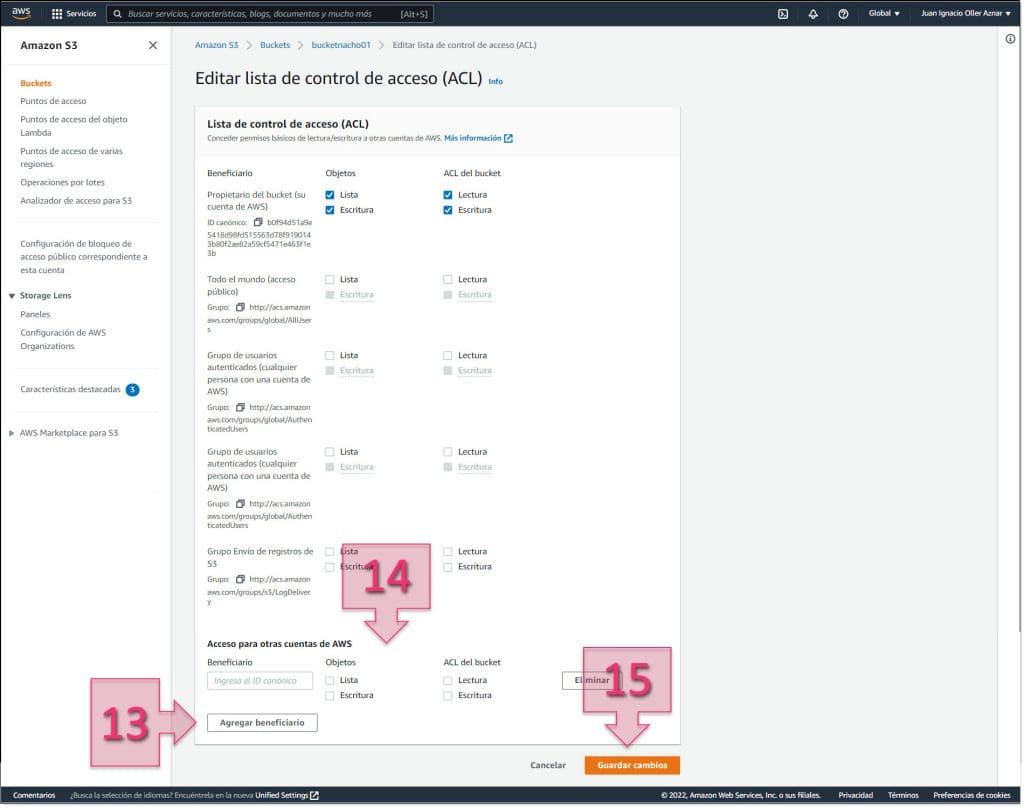
Con esto tendremos preparado el S3 para la exportación y podremos pasar al siguiente paso.
Paso 3. Proceso de extracción de la máquina virtual de AWS
Lo primero que haremos en esta sección es localizar el identificador de la instancia (máquina virtual) que se quiere migrar.
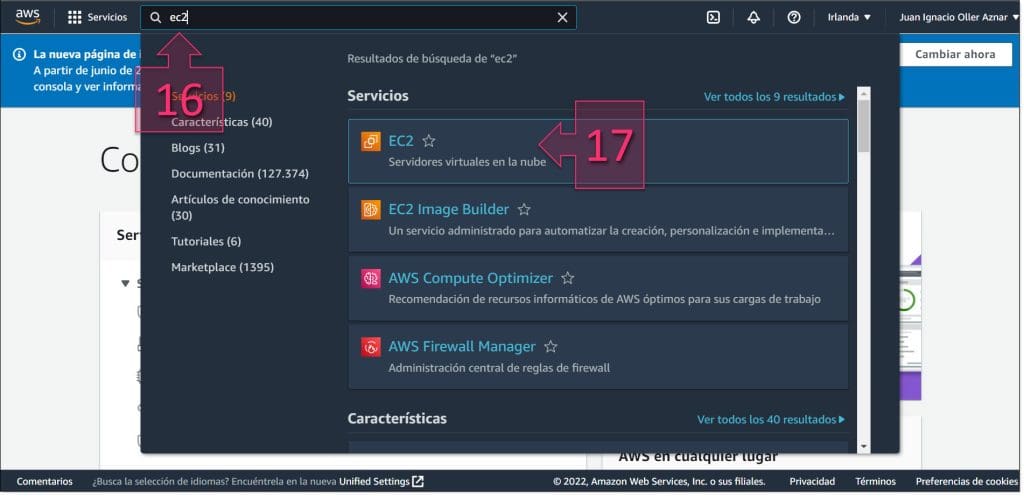
Para ello, se debe ir a “EC2” (Elastic Cloud Computing) o lo que es lo mismo, las máquinas virtuales de AWS. Para ello se debe escribir “EC2” en la barra superior (16) y hacer clic sobre “EC2: Servidores Virtuales en la Nube” (17).
En la ventana inicial de EC2, se debe hacer clic en “Instancias” (18) para acceder a la sección donde se muestran todas las instancias, estén o no en ejecución.
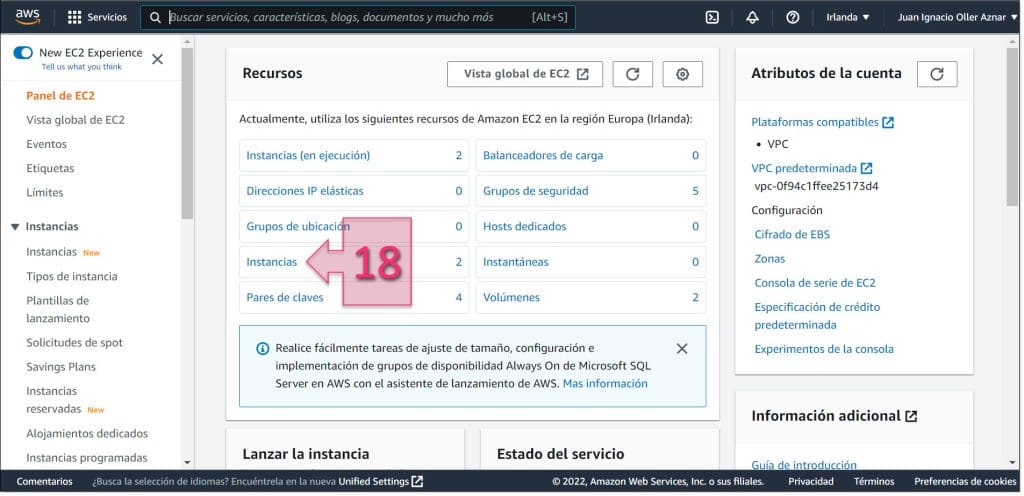
En este momento, se debe localizar la instancia que se quiere migrar y copiar el “ID de la instancia” (19). Este ID lo reservamos para usarlo más adelante, dentro de este mismo punto.
Lo siguiente que se debe hacer es extraer los datos de conexión de nuestro usuario de AWS para poder lanzar una consola de PowerShell desde nuestro PC y poder ejecutar los comandos
NOTA: En el caso de Windows se usa la consola de PowerShell mientras que en el caso de GNU/Linux se hará desde la consola.
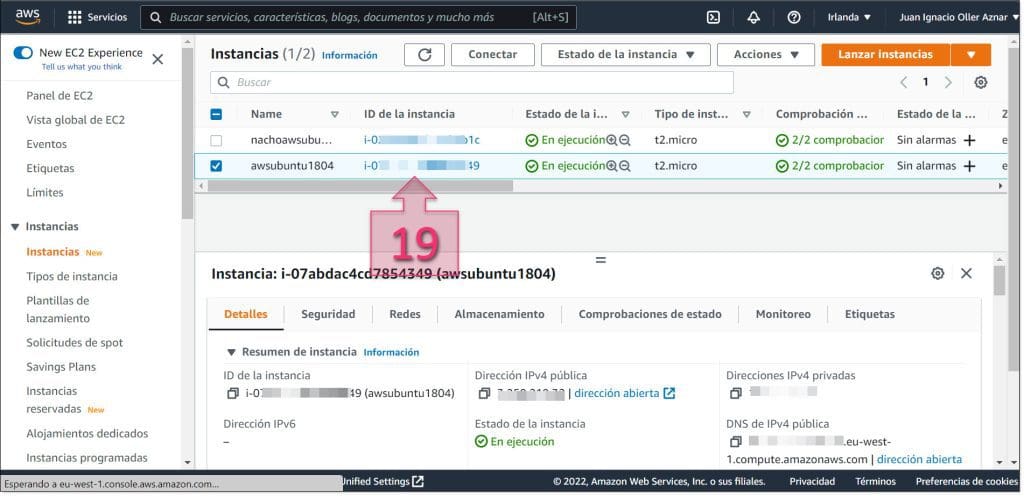
Estos datos se pueden extraer accediendo al perfil del usuario, a través de la parte superior de la consola Web de AWS. Para ello se debe hacer clic en el nombre de usuario (20) y seleccionar “credenciales de seguridad” (21).
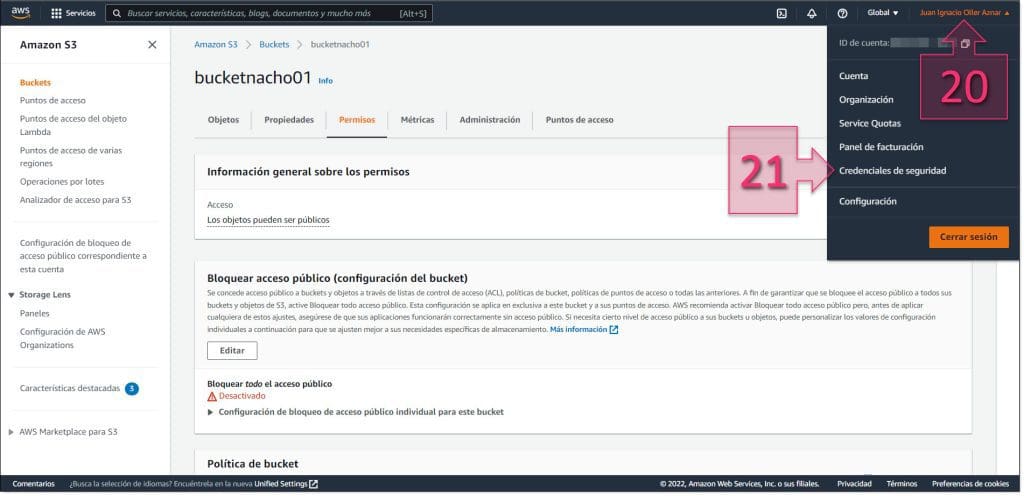
Una vez dentro de “credenciales de seguridad” se debe desplegar “Claves de acceso (ID de clave de acceso y clave de acceso secreta)” (22)
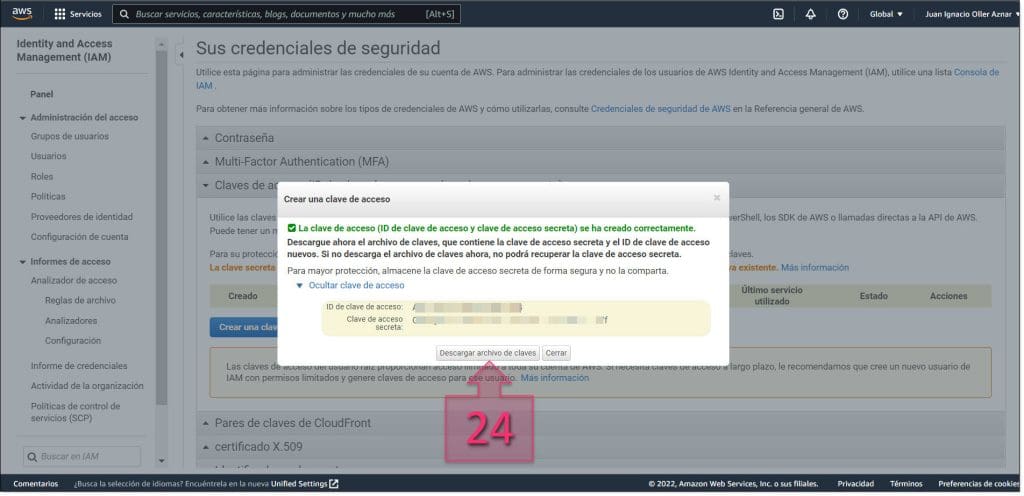
Dentro de esta sección, se deben crear las nuevas claves para la conexión, por lo que se debe hacer clic en “Crear una clave de acceso” (23).
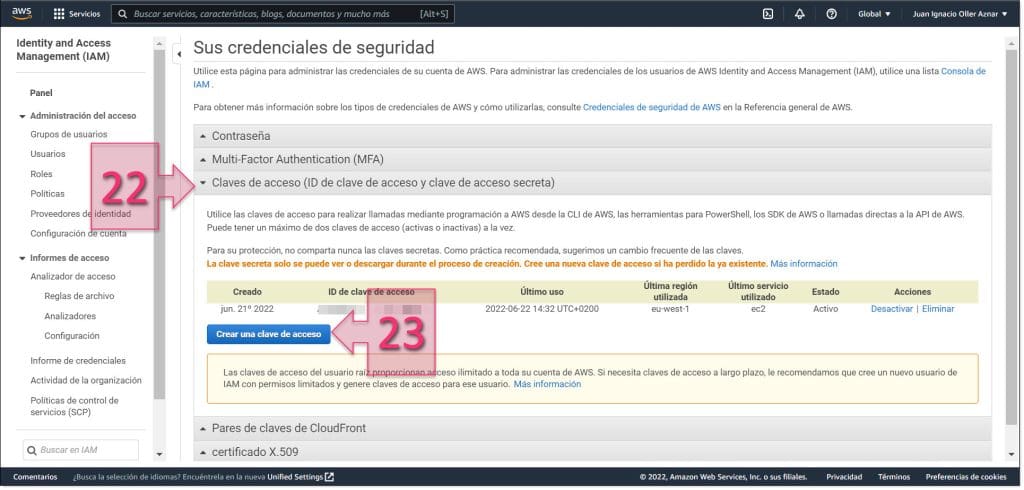
Una vez hecho esto, se mostrará una ventana emergente en la que se podrá ver el “ID de clave de acceso” y la “clave de acceso secreta”.
En este momento, debemos hacer dos cosas, por un lado, copiar esos datos, que son los que usaremos para la conexión desde PowerShell y por otro, hacer clic en “Descargar archivo de claves” (24) y guardarlo en nuestro equipo.
Ahora que ya tenemos los datos de conexión, estamos listos para lanzar la consola de PowerShell (que deberá lanzarse con permisos de Administrador para evitar problemas) y realizar una serie de operativas.
Una vez comprobado, abrimos un editor de texto, como por ejemplo Notepad++ o gVim para crear un archivo llamado “file.json” con el siguiente contenido:
{
«DiskImageFormat»: «VHD»,
«S3Bucket»: «bucketnacho01»,
«S3Prefix»: «vms/»
}
Donde:
- “DiskImageFormat” se refiere al formato en el que se extraerán los servidores, que en este caso será VHD para poder ser importada dentro de Jotelulu.
- “S3Bucket” debe ser el nombre del bucket que hemos creado y que recibirá la exportación de la instancia en formato VHD.
- “S3Prefix” se defiere a la carpeta generada para almacenar lo extraído.
Una vez creada y almacenada en una ruta de nuestro equipo, debemos tomar nota de esa ruta para incluirla en el comando que se ejecutará a continuación.
NOTA: En el caso de GNU/Linux se debe añadir permiso de lectura sobre este archivo.
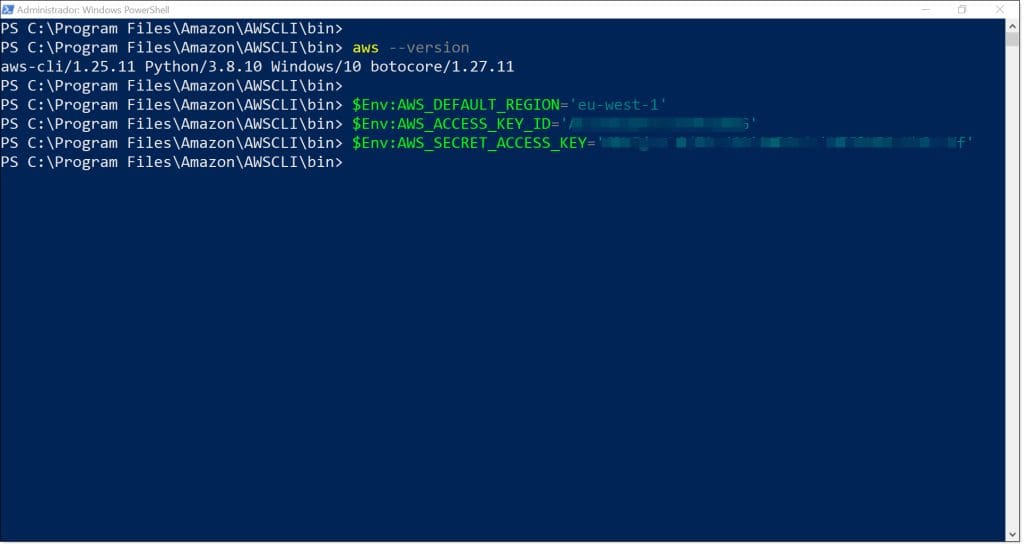
Dentro de la consola de PowerShell, necesitaremos que nuestro sistema se valide frente a nuestra suscripción de AWS, por lo que se deberán cargar las variables de entorno, que serán tres:
- $Env:AWS_DEFAULT_REGION=’REGION_DE_NUESTRA_MAQUINA_Y_S3′
- $Env:AWS_ACCESS_KEY_ID=’CLAVE_DE_ACCESO’
- $Env:AWS_SECRET_ACCESS_KEY=’ CLAVE_DE_ACCESO_SECRETA’
Los datos que se deben usar son los que se han obtenido anteriormente.
Un ejemplo podría ser:
- $Env:AWS_DEFAULT_REGION=’eu-west-1′
- $Env:AWS_ACCESS_KEY_ID=’BEGHC3T2OQ53AJHKIAZA’
- $Env:AWS_SECRET_ACCESS_KEY=’DGIjWLv0w/ad Ei1960e8ehUVfwRSTKhGrFlXE6rs’
La forma de lanzarlas es escribir directamente el texto en la consola ().
$Env:AWS_DEFAULT_REGION=’eu-west-1′
$Env:AWS_ACCESS_KEY_ID=’BEGHC3T2OQ53AJHKIAZA’
$Env:AWS_SECRET_ACCESS_KEY=’DGIjWLv0w/ad Ei1960e8ehUVfwRSTKhGrFlXE6rs’
Para comprobar la operativa en PowerShell, y comprobar si se han cargado correctamente las variables de entorno, se puede lanzar el comando «echo» seguido del nombre de la variale de entorno, haciendo una consulta como la siguiente:
echo $Env:AWS_DEFAULT_REGION
echo $Env:AWS_ACCESS_KEY_ID
echo $Env:AWS_SECRET_ACCESS_KEY
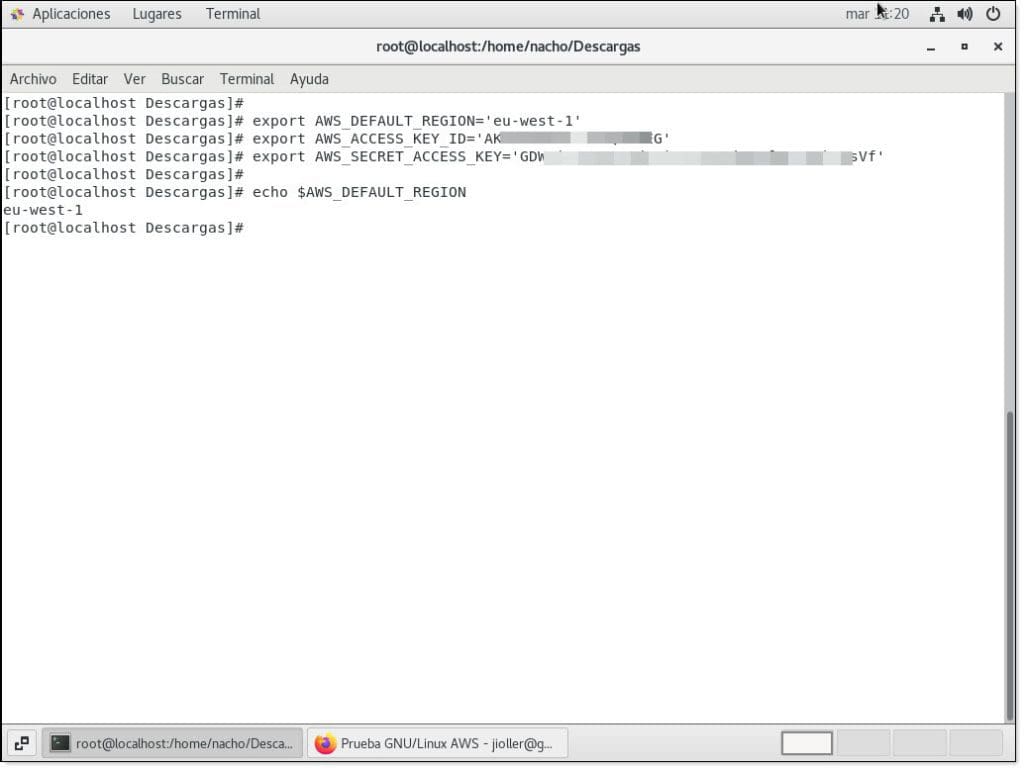
En el caso de GNU/Linux lo haríamos mediante el comando “export”, de la siguiente manera:
export AWS_DEFAULT_REGION=’eu-west-1′
export AWS_ACCESS_KEY_ID=’BEGHC3T2OQ53AJHKIAZA’
export AWS_SECRET_ACCESS_KEY=’DGIjWLv0w/ad Ei1960e8ehUVfwRSTKhGrFlXE6rs’
Y podríamos comprobar que se han cargado lanzando un “echo” de cualquiera de ella, anteponiendo un símbolo dólar ($).
echo $AWS_DEFAULT_REGION
Y en este caso, nos devolvería “eu-west-1” o lo que es lo mismo, el contenido de dicha variable del sistema.
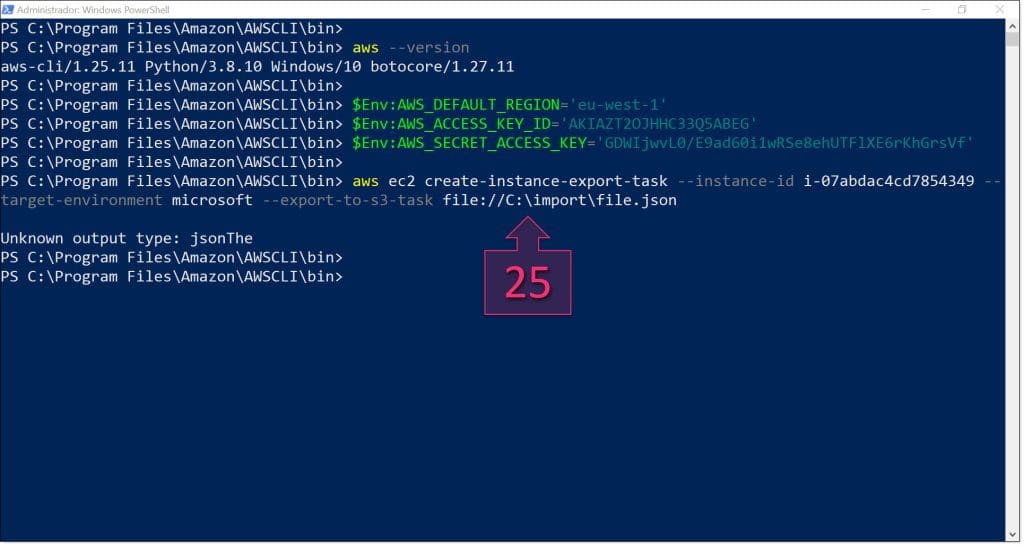
A continuación, se debe lanzar el comando “aws ec2 create-instance-export-task” (25) para desencadenar la exportación de la máquina virtual.
aws ec2 create-instance-export-task –instance-id <ID-INSTANCIA> –target-environment microsoft –export-to-s3-task file://<RUTA-AL-FICHERO>
Donde:
- <ID-INSTANCIA> debe ser sustituido por el ID de la instancia o máquina virtual que hemos extraído previamente.
- <RUTA-AL-FICHERO> debe representar la ruta donde se almacena el archivo “file.json”.
Un ejemplo podría ser:
aws ec2 create-instance-export-task –instance-id i-whahahaha –target-environment microsoft –export-to-s3-task file://C:\import\file.json
De la misma manera, se podría lanzar el comando desde un GNU/Linux, usando una sintaxis idéntica, que cambiaría en el caso de la ruta al archivo “file.json”.
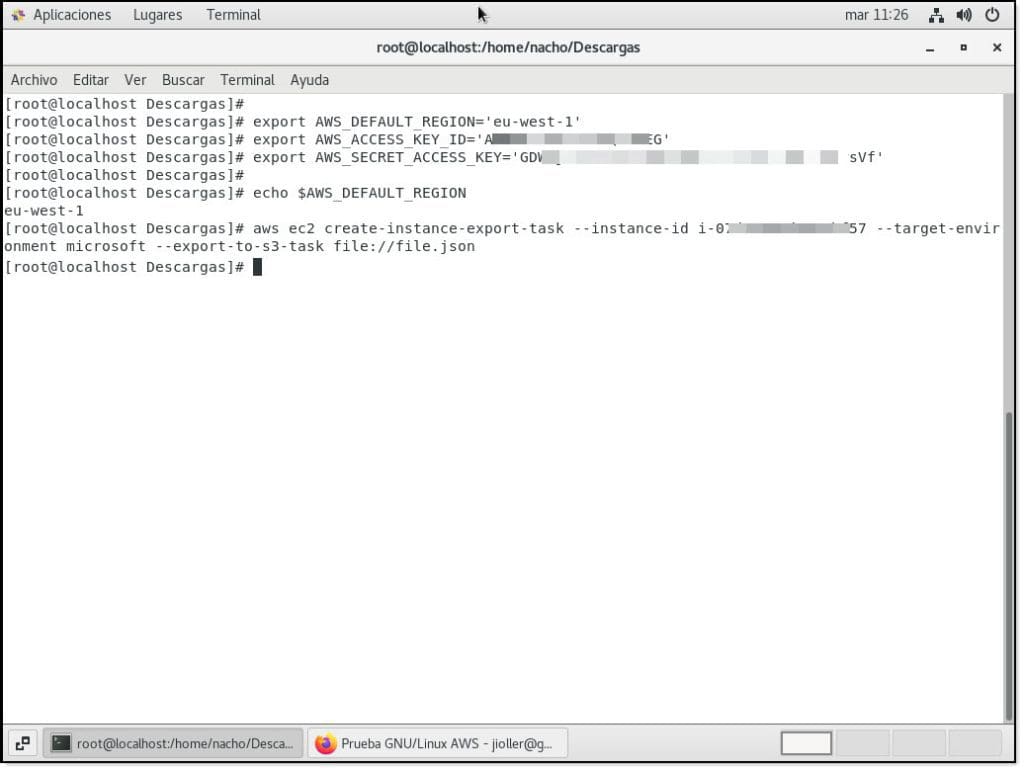
A continuación, se debe navegar hasta el bucket de S3 para ver si se han copiado los datos.
NOTA: Es un proceso que puede variar mucho en su tiempo de ejecución, y este tiempo variará en función del tamaño del servidor que se quiere exportar.
Una vez localizado el bucket al que se ha exportado la máquina virtual, se deberá hacer clic en el nombre (26) para entrar dentro del mismo.
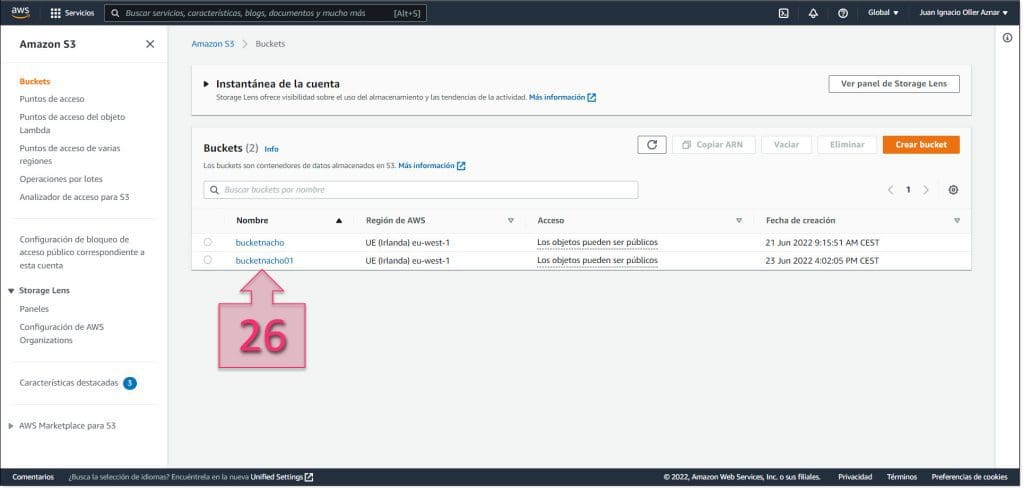
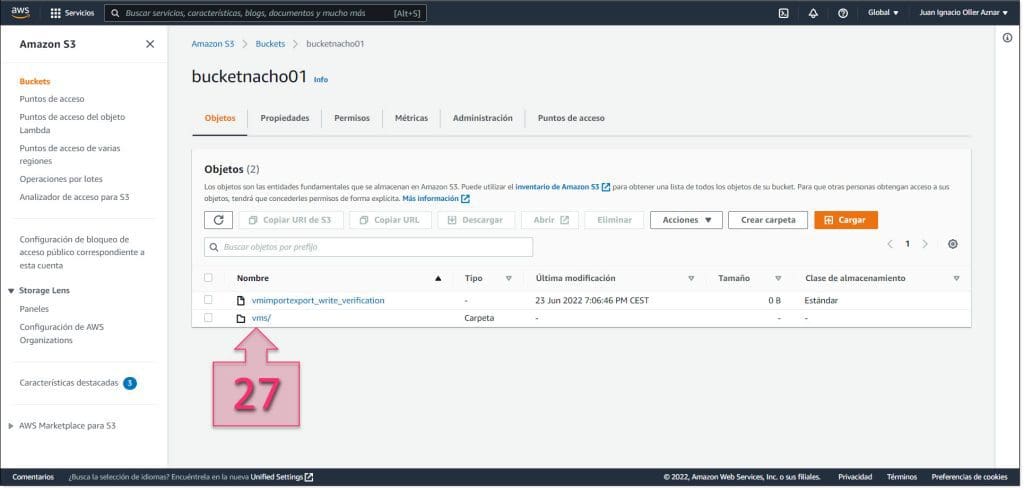
A continuación, se debe localizar la carpeta donde se han guardado los ficheros exportados (27) y que hemos definido previamente en el fichero “file.json”, que en el caso de este ejemplo ha sido /vms”.
En este momento, si ha ido todo bien, se tendrán dos opciones, descargar el VHD directamente (28), o copiar la URL (29) para usarla en el siguiente paso, para su migración a Jotelulu.
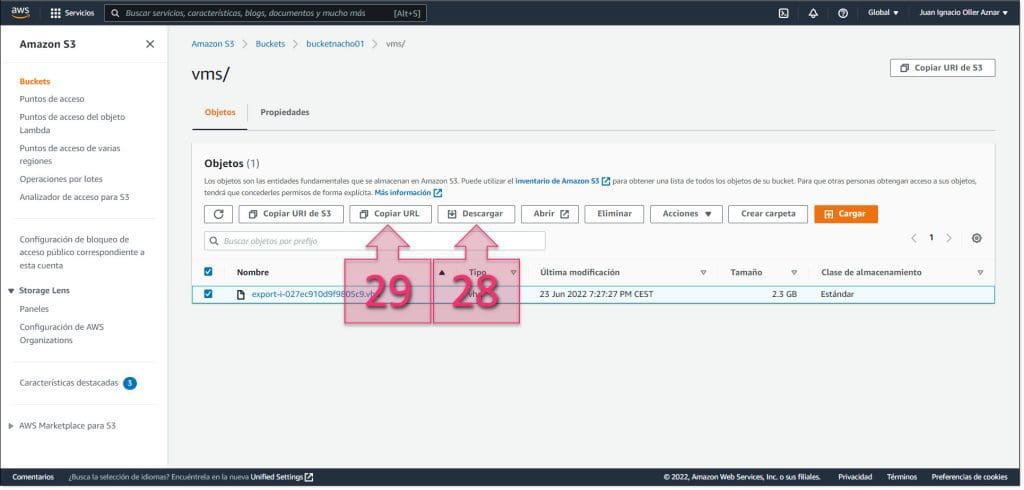
Con esto, habremos finalizado la operativa en la parte de AWS.
Paso 4. Subida de la máquina a Jotelulu
Para comenzar el proceso de migración en la parte de Jotelulu se debe lanzar el menú de migraciones ubicada en la Zona Partners una vez en el se debe hacer clic en “Nueva migración” (30).
NOTA: La apariencia de esta ventana inicial variará en caso de haber realizado migraciones previas, ya que se podrá ver un listado de elementos migrados.
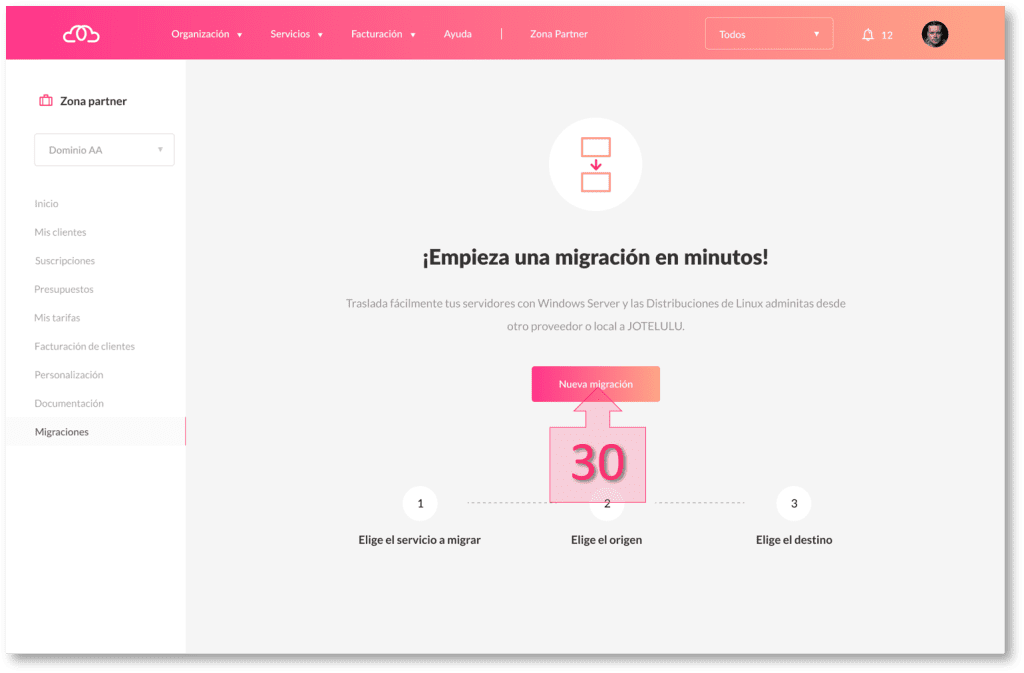
En este momento comenzará un menú guiado en el que se deberán ir marcando una serie de selecciones que prepararán el sistema para la carga del servidor en Jotelulu.
Lo primero que se deberá seleccionar es el tipo de servicio a migrar, que en este caso será el servicio de Servidores, por lo que se deberá marcar “Servidores” (31) en el menú.
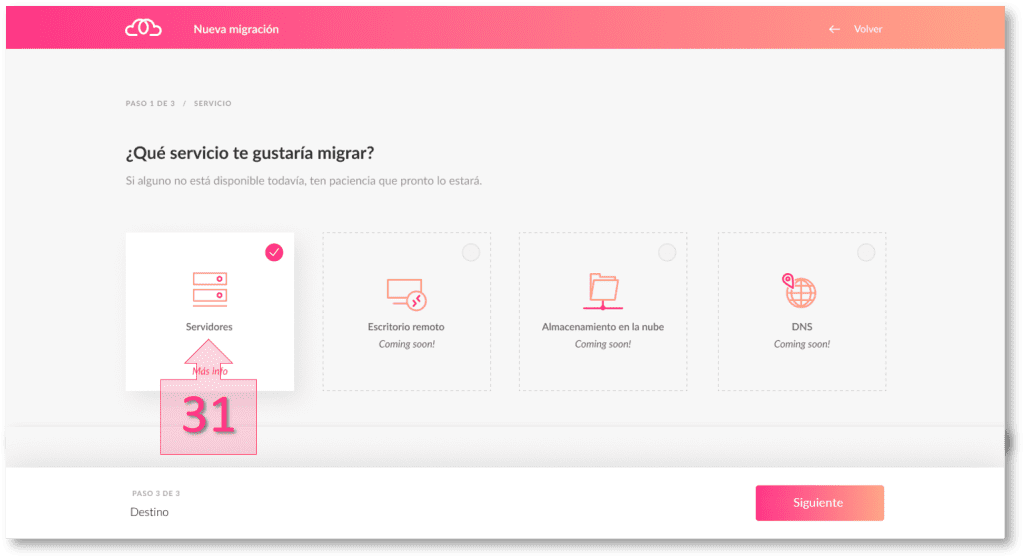
A continuación, se deberá marcar si se quiere seleccionar un servidor de tipo físico o de tipo virtual. En este caso, la migración es de tipo virtual por lo que se debe marcar “Virtual” (32) en el menú y seguir avanzando.
El siguiente apartado muestra la forma en que se cargará el disco que se va a importar. Se debe seleccionar “Discos Virtuales Compatibles” (33) ya que es el formato en el que se entrega desde AWS.
También se debe seleccionar la forma en que se hace la entrega de este disco virtual a Jotelulu, que, en este caso, a pesar de poder hacerlo por dos medios, mediante FTP o mediante la descarga mediante URL, se optará por marcar “descarga mediante URL” (34) ya que es un medio más rápido, al evitar la intermediación del cliente.
NOTA: Cuando se haga la subida mediante URL, se tendrá que hacer desde el equipo en el que se ha hecho toda la operativa de AWS.
Debemos proporcionar los datos de los Discos Virtuales a importar (35), para ello debemos poner el nombre del fichero a importar, que deberá incluir la extensión (definido en el Paso 3), la URL del disco a importar, facilitada desde el bucket en el Paso 3, deberemos seleccionar también si es un disco de sistema o de datos (el principal del sistema operativo deberá ser de sistema, todos los demás podrán ser de datos), y por último, el nombre del disco a mostrar, que será el nombre por el que se identificará posteriormente dentro de la consola.
Por último, se deber hacer clic en “Siguiente” (36) para que se guarden los datos y se continúe con el despliegue.
Se tendrá que asignar información sobre la organización, suscripción, y zona de disponibilidad (37) a la que se quiere subir este nuevo disco. Esto variará en función de las organizaciones y suscripciones que tenga asignadas el cliente, por lo que en caso de tener varias, podrá seleccionar una u otra según sean sus necesidades, en caso de tener una única, solo se podrá seleccionar esta. En el caso de la zona de disponibilidad, el cliente puede operar de igual forma que en el resto de los servicios.
La última selección de este apartado ¿Quieres desplegar un nuevo servidor con los discos duros importados? (38) Se deberá decir si se quiere desplegar o no esta máquina virtual en este momento, o si quiere dejar la imagen subida para futuros usos. Lo más usual, será que se seleccione la opción “Sí”.
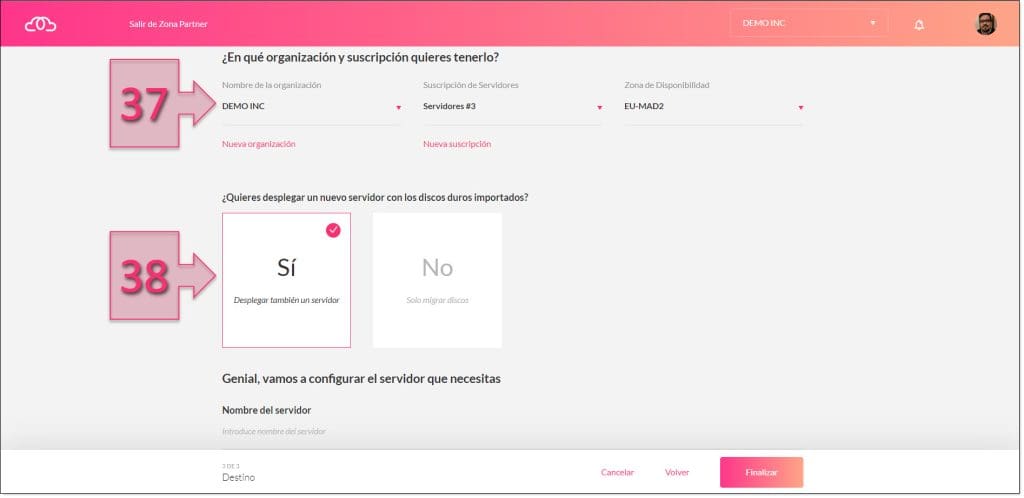
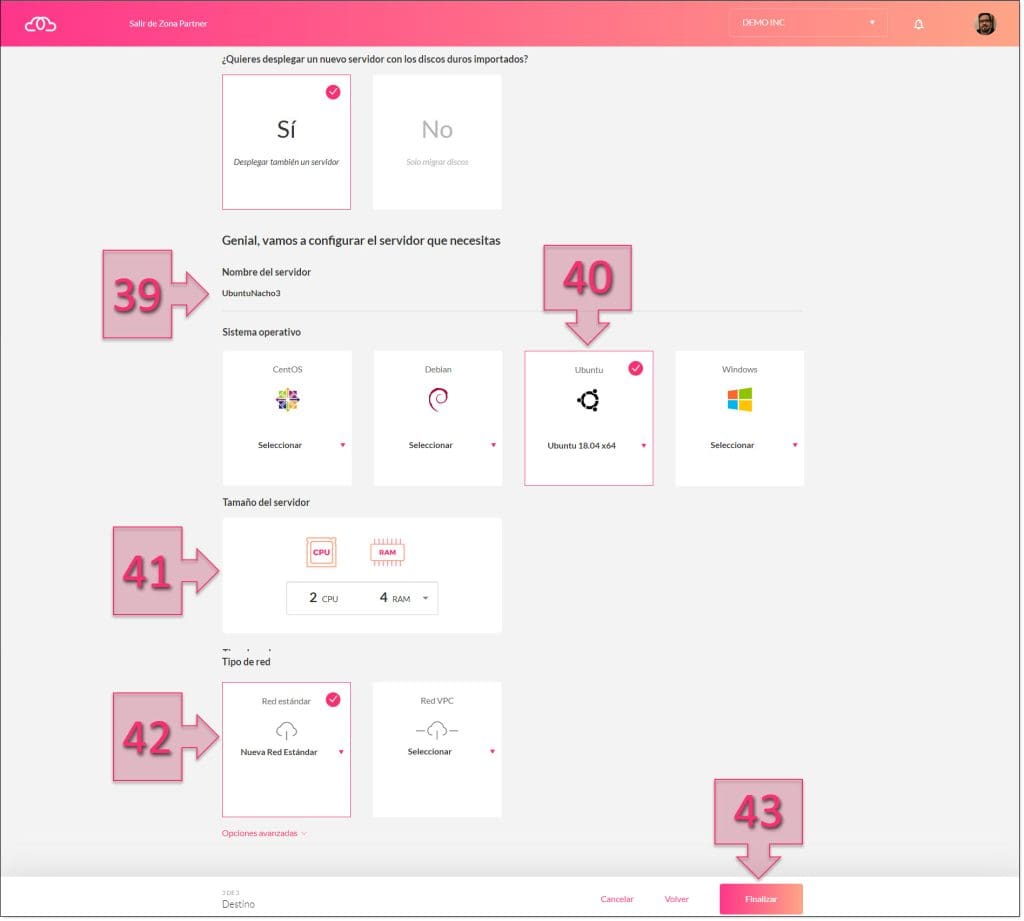
Al seleccionar “Si”, se despliega toda la configuración del servidor que se va a migrar y se deberá seleccionar toda la información relativa a la forma en que quedará configurado en nuevo servidor dentro de Jotelulu.
Lo primero que se tendrá que hacer en esta nueva sección es dar un nombre de servidor (39), que, en este caso, al ser la forma en que se identificará, puede contener espacios.
Después se deberá seleccionar el sistema operativo (40) que ejecuta este nuevo servidor.
El siguiente paso, será seleccionar el tamaño del servidor (41), donde se describirá la capacidad de cómputo de este, definida por la CPU y la RAM, y que deberá dimensionarse en arreglo a las necesidades del cliente.
Por último, se debe seleccionar el Tipo de red (42) en función de si se necesita una red estándar o una VPC.
Por último, se deberá hacer clic en “Finalizar” (43).
Una vez finalizado este proceso, se han establecido las bases para la migración del servidor en la parte de Jotelulu y se desencadenarán una serie de procesos internos que desembocarán en el despliegue del nuevo servidor en la plataforma de Jotelulu, que será accesible dentro de la suscripción de servidores contratada por el cliente.
Conclusiones y próximos pasos:
El proceso de migración de servidores entre nubes suele ser complejo, pero en Jotelulu siempre intentamos diseñar nuestros procesos y nuestras herramientas pensando en la simplicidad y comodidad de nuestros clientes.
Por esta razón, la migración de un servidor desde AWS a la nube de Jotelulu es un proceso sencillo y completamente guiado a través de nuestra plataforma, con la que podrás unirte a nuestra familia sin tener ningún percance en el camino, pero si los tuvieras, no dudes en contactar con nosotros para que podamos echarte una mano.
Si por algún casual, este contenido os hubiera suscitado interés y quisierais saber más sobre otro proceso de migración en concreto, no dudéis en consultar los siguientes tutoriales:
- Guía rápida de la herramienta de Migraciones
- Cómo migrar un servidor desde VM-Ware a Jotelulu.
- Cómo migrar servidores Windows desde entornos on-premise a Jotelulu.
- Cómo migrar servidores GNU/Linux desde entornos on-premise a Jotelulu.
- Cómo migrar una máquina virtual de MS Azure a Jotelulu.
- Cómo migrar un servidor desde Hyper-V a Jotelulu.
¡Bienvenido a Jotelulu!