Cloud y sistemas
Acompáñanos en este artículo en el que vamos a hablar de qué es y cómo funciona ReFS, el sistema de ficheros resiliente que se ha ganado el corazón de administradores de sistemas de plataformas de Microsoft a lo largo de todo el mundo.
Resilient File System (ReFS) es un sistema de ficheros diseñado por Microsoft con la intención de garantizar un uptime óptimo para nuestros datos, soportando condiciones que sus predecesores no eran capaces de soportar y garantizando a su vez una capacidad de crecimiento casi infinita.
ReFS es un sistema diseñado por el gigante de Redmond para tomar el relevo del longevo NTFS del que ya hablamos en este artículo Qué es NTFS y sus características principales de este mismo blog.
Al ser un sistema de ficheros con tantos años de existencia, NTFS ya no cumplía con las necesidades de un mercado con una demanda desmesurada de storage y que además solicitaba ciertos requerimientos adicionales de seguridad.
Esto hizo que ReFS desde su concepción tuviera en mente varios puntos clave como la verificación de la integridad de manera continua, la depuración de los errores que se encuentran de manera proactiva y por tanto la necesidad de mantenimiento manual por parte del operador en base a chequeos de disco o similares (ejemplo chkdsk).
Además, ReFS, en ese diseño mejoraba aspectos como la longitud de las rutas y los nombres de archivo, los metadatos, la estructura de cara a los RAID o la virtualización, y por supuesto, tal como hemos comentado, el soporte de redundancia y tolerancia a fallos.
ReFS fue liberado junto a Windows Server 2012 el uno de agosto de 2012 y desde entonces ha pasado por múltiples revisiones, de las cuales la última ha sido la 3.7 que vino de la mano de Windows Server 2022.
A lo largo de las próximas líneas desarrollaremos un poco más por qué ReFS es un buen sistema de ficheros y porque deberíamos usarlo en nuestros sistemas de almacenamiento.
Imagen. Creación de nuevo volumen simple ReFS
Resiliencia del sistema de ficheros
Comenzaremos hablando de la resiliencia del sistema, para ver si hace honor a su nombre y es un sistema de ficheros tan resistente como nos venden nuestros amigos de Microsoft.
- Corrección proactiva: ReFS implementa un analizador de integridad de los datos que no solo valida que los datos que se van a escribir son correctos y que estos son correctos en el destino mediante una acción comparativa, sino que además realiza una tarea de análisis de los datos de manera programada cada x tiempo. Esto es lo que se llama “limpieza”, que identifica cualquier tipo de error o daño en el sistema de ficheros para corregirlo de manera automática.
- Secuencias de integridad: ReFS, al igual que hacía NTFS usa el checksum o sumas de comprobación para establecer si los datos han sido manipulados o siguen siendo los mismos que deberían ser, para comprobar su veracidad y que no ha habido daños en las copias.
- Eliminación de datos inútiles: Si se produjeran daños en un volumen de los que no hubiera una copia alternativa, ReFS consideraría el resto de los datos que constituyen esa copia inútil, eliminándolos del espacio de nombres.
- Mantenimiento online: ReFS mantendrá los volúmenes dañados en línea incluso mientras se reparan para garantizar el servicio. Esto será así a menos que los daños sean de tales dimensiones que no se pueda garantizar que no haya fallos de acceso, en cuyo caso lo dejará offline mientras lo trata.
- Reconstrucción de espejos: Si se usan espacios de almacenamiento con espejos o con paridad se podrá realizar el mantenimiento online de los sistemas.
Elasticidad
Nuestros amigos de Redmond están obsesionados con la adaptación de los sistemas a las necesidades cambiantes para sus clientes, motivo por el que se pretende que ReFS sea capaz de crecer y decrecer de manera ágil.
ReFS es capaz de crecer hasta un tamaño de 35 PB (petabytes) de tamaño de archivo máximo e igual tamaño para tamaño máximo de volumen, lo que lo deja a eones de NTFS que solo soporta 256 TB (terabytes).
Estos tamaños, según las especificaciones de Microsoft, se pueden alcanzar sin afectar ni lo más mínimo al rendimiento, cosa que suponemos que dependerá de entornos teóricos ideales o de equipamientos de gran coste y alejados del común de los mortales.
Rendimiento
Como el apartado de elasticidad lo terminábamos hablando del rendimiento del sistema para determinados escalados, nos parece lo más acertado continuar con este punto.
ReFS ha sido rediseñado de principio a fin y se pusieron en el foco tanto la resistencia como el rendimiento por lo que es un sistema capaz de soportar grandes volúmenes de tamaño, con grandes cantidades de accesos de escritura y lectura sin penalización del rendimiento.
Además, debemos tener en cuenta que está especialmente diseñada para entornos virtualizados, por lo que lo hace ideal para entornos de nube privada, pública o híbrida.
El rendimiento de el sistema de ficheros resiliente se basa por ejemplo en una gestión de la paridad más rápida y menos farragosa que hasta ahora, es lo que se llama paridad acelerada por reflejo. Esta paridad se basa en la aplicación de unos niveles, que son volúmenes lógicos que permiten acceder más rápido a los datos tanto para los datos de uso frecuente (hot storage) como para el archivo profundo (cold storage).
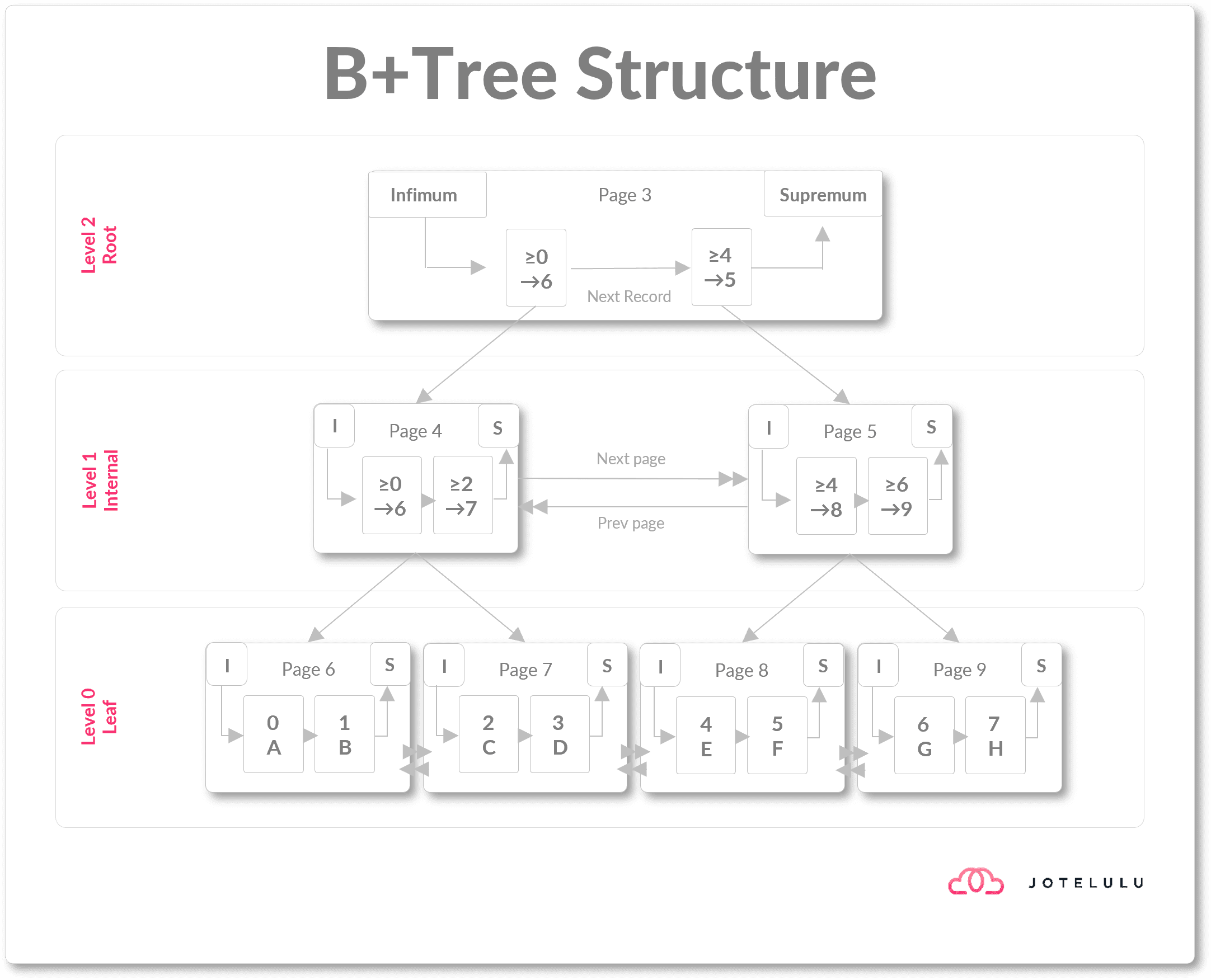
Imagen. Estructura de ficheros basada en niveles B+Tree
Otro punto a tener en cuenta es que este sistema de ficheros ya ha sido diseñado teniendo en cuenta el uso de discos híbridos o aquellos que tienen almacenamiento flash, por lo que se hace uso de este tipo de tecnologías para acelerar el acceso tanto de escritura como de lectura de los datos.
Tal como hemos comentado previamente, este sistema de ficheros está pensado para trabajar con virtualización por lo que tiene opciones como el VDL (longitud de datos válida) disperso, que permite reducir significativamente el tiempo usado para la creación de los VHD (discos duros virtuales).
Por último, permite realizar clonaciones de bloques, por lo que se aceleran las operaciones de copia de datos de manera notable reduciendo además los tiempos de creación de puntos de control o las tareas de combinación de los discos virtuales.
NOTA: Para mantener una implementación correcta de ReFS debe consultar Windows Server Catalog para ver el hardware que Microsoft certifica para estas implementaciones.
Conclusiones y siguientes pasos:
Hemos visto a lo largo del artículo que es y cómo funciona ReFS, el sistema de ficheros resiliente con gran capacidad de resistencia frente a distintas eventualidades, escalabilidad y adaptación, bajo nivel de requerimientos de mantenimiento por parte de los administradores y con unas mejores prestaciones que el longevo NTFS.
En próximos artículos y tutoriales trataremos esta tecnología de filesystem para que puedas aprovechar toda su potencia para mejorar el servicio de ficheros de tu organización.
Si quieres aprender más de NTFS, además de consultar el artículo Qué es NTFS y sus características principales te recomendamos echar un ojo a la Configuración de permisos NTFS de nuestro blog.
¡Gracias por acompañarnos!
13 de marzo de 2023