Recursos Sysadmin
Quédate con nosotros a lo largo de este viaje donde trataremos cuáles son las 10 principales preocupaciones al montar un Disaster Recovery en una pyme.
Planificar, montar y mantener un plan de Disaster Recovery (Recuperación de Desastres) realmente funcional y efectivo requiere de una planificación concienzuda y la gestión de diversos factores.
El esfuerzo invertido en la preparación de los planes de contingencia, en el despliegue de infraestructuras alternativas, de procesos y operativas, así como de concienciación y formación del personal antes de que se produzca la incidencia son elementos clave para asegurar la recuperación de las operaciones de la empresa de manera rápida y eficiente después de un desastre.
Una correcta inversión en una solución de Recuperación de Desastres (DR) correctamente diseñada y ejecutada no solo protegerá los activos críticos de la organización, sino que además garantizará la continuidad del negocio y la resiliencia frente futuras contingencias.
NOTA: Normativamente hablando, estos procedimientos, operaciones y planes quedan recogidos dentro de la ISO/UNE/22.301 “Sistemas de Gestión de Continuidad de Negocio”.
Listando las preocupaciones al montar un Disaster Recovery:
Como somos mega-fans de las listas, hemos decidido presentar este artículo sobre las preocupaciones y los desafíos como una lista de las 10 principales preocupaciones que toda pequeña empresa tiene a la hora de enfrentar el reto de montar un DR.
Sin más dilación, vamos al turrón:
- El alineamiento con la organización.
- Evaluación del riesgo y análisis del impacto.
- Coste de la solución y falta de presupuesto.
- Dependencias y coordinación.
- Definición de los objetivos de recuperación.
- Procedimientos, documentación y normas.
- Tecnologías usadas frente a tecnologías adecuadas.
- Formación y concienciación.
- Pruebas, operativas y validación.
- Mejora continua del Disaster Recovery.
Como siempre, a continuación, empezaremos a tratar cada uno de ellos en más o menos profundidad.
El alineamiento con la organización:
Este paso no lo voy a desarrollar demasiado porque es algo muy sencillo de comprender y es muy sencillo de implementar si es que planificamos con un mínimo de cabeza. Lo primero que debemos comprender cuando nosotros planteamos un plan de DR, es que nosotros, como departamento de IT, no somos el ombligo del mundo, sino que somos un departamento que posibilita el correcto funcionamiento de la empresa, pero no somos el core (al menos en la mayoría de las empresas).
Por tanto, debemos reunirnos con el resto de los departamentos y la dirección para definir qué es lo más importante, qué es lo que no se puede parar en ningún momento y qué es lo que tiene prioridad en la recuperación del negocio.
Evaluación del riesgo y análisis del impacto:
La evaluación del riesgo es uno de los puntos fundamentales para proteger nuestra organización. Consiste, valga la redundancia, en identificar los riesgos específicos que podrían impactar a nuestra organización para elaborar estrategias para su gestión. Dentro de estos podemos encontrar cosas tan diversas como fallos de hardware o software, errores humanos, actos intencionados por parte de insiders, desastres naturales, e incluso los famosos ciberataques.
Este tema lo tratamos en el artículo Cómo evaluar riesgos y amenazas en la pyme, por lo que no vamos a tratarlo en este artículo, dejando al lector la decisión de si quiere seguir por ese camino o no.
Además del modelo de evaluación de riesgos, se tiene el Análisis de Impacto en el Negocio (BIA), que se encarga de determinar cómo los diferentes tipos de desastres afectan a la organización, evaluando el impacto financiero, el operativo y de reputación asociado con cada riesgo que haya sido identificado previamente.
Coste de la solución y falta de presupuesto:
En todo proyecto, el coste de la solución es uno de los puntos más delicados, ya que es un condicionante realmente severo que hará que podamos desarrollar un proyecto de una manera o de otra, siendo la solución más completa la más cara como es menester. En este sentido, un proyecto de implantación de Disaster Recovery no escapa a esta norma general de los proyectos y por lo general, dependiendo de como se organice, las soluciones pueden ser realmente caras lo que hace que nos encontremos ante un panorama de falta de presupuesto.
Dentro del coste de la solución se deben tener en cuenta varios conceptos como son el coste de implantación o inicial y el coste de mantenimiento de la solución, además de ciertos indicadores que nos ayudarán a determinar el balance entre el coste de la implantación frente al beneficio que la solución genera.
Dentro del coste inicial, debemos tener en cuenta tanto el coste del personal implicado (horas de trabajo, contratación de asesores si los hay, etc.) y los costes asociados a infraestructura como por ejemplo los asociados a servidores y otro hardware, los costes de las licencias, costes de suscripciones de servicios, y proveedores de servicio cloud, etc.
Además, habrá que tener en cuenta toda la relación del coste de mantener una posición vigilante en lo que respecta a la seguridad, que lógicamente tiene un coste frente a la inacción, que puede llevarnos a situaciones en las que el impacto de una brecha en el negocio llegue a ser catastrófica.
Sobre este tema recomendamos leer el artículo Cuál es el coste real de no invertir en seguridad de nuestro blog.
Dependencias y coordinación:
Los sistemas y procesos no son entes independientes que flotan en la nada, sino que existen infinidad de interdependencias entre todos los elementos que componen nuestra organización.
Para poder crear un plan de DR funcional, se deben revisar esas interdependencias entre los distintos sistemas de manera que queden correctamente identificados y documentados para asegurarnos de que la recuperación de los procesos del negocio es eficiente y coordinada.
Otro de los puntos para tener en cuenta es el trato con los socios comerciales y con los proveedores, de manera que podamos asegurar que todos los stakeholders críticos para la organización participen en nuestros planes de DR o tengan otros planes compatibles con el nuestro y que puedan ser coordinados en caso de que se produzca un detalle.
Estos planes es conveniente revisarlos y practicarlos de manera más o menos frecuente para asegurarnos de que no queden meramente en el marco teórico.
Por otro lado y por encima de todo, se debe tener una clara integración con la dirección y el claro apoyo de esta ya que sin el apoyo de la dirección es posible que se quede en agua de borrajas.
Definición de los objetivos de recuperación:
Aquellos que tengan un poco de recorrido en la gestión de proyectos de informática sabrán, bien por experiencia o bien por haberlo aprendido en algún curso, que la mayoría de los proyectos de IT sufren algún tipo de problema a lo largo de su ejecución. De hecho, los estudios dicen que únicamente en torno al 20% se ejecutan de manera completamente satisfactoria.
Aquellos que hayan estudiado metodologías como por ejemplo PMP, ACP o incluso Scrum, sabrán que en la mayoría de los casos esto se debe a una gestión errónea de requisitos y de definición de los objetivos del proyecto, por eso, en el caso de montar un plan de recuperación frente a desastres (DR), debemos tener claros los objetivos desde antes de empezar con el proyecto, deben ser la piedra sobre la que empecemos a construir.
Los objetivos de recuperación que debemos establecer deberán partir de un conocimiento de los recursos y servicios de nuestra organización, así como del conocimiento de las conexiones y dependencias que estos puedan tener y serán principalmente dos:
- Objetivo de Tiempo de Recuperación (RTO).
- Objetivo de Punto de Recuperación (RPO).
A modo de introducción breve, diremos que el “Objetivo de Tiempo de Recuperación (RTO)” establece el tiempo máximo en el que se debe restaurar los procesos críticos de la organización después de haberse producido un incidente. Mientras que el “Objetivo de Punto de Recuperación (RPO)” establece la cantidad máxima de datos que se pueden perder desde la última copia de seguridad, siendo una unidad medida en tiempo.
NOTA: Se puede ampliar la información sobre este tema en el artículo Disaster Recovery: Qué son RPO, RTO, WRT o MTD de nuestro blog.
Procedimientos, documentación y normas:
Dentro de la filosofía de la gestión de servicios, se suele decir que hay tres puntos clave que hacen que todo funcione si se engranan correctamente, estos se componen de la terna “Personas Procesos y Tecnología” que finalmente se transforman en una correcta estrategia de gestión del conocimiento. Dentro de esta gestión del conocimiento, en este caso, nos centraremos en los procesos que posibilitan que tanto nuestro equipo sepa que se debe hacer a cada momento y que en casos como el del DR es de suma importancia.
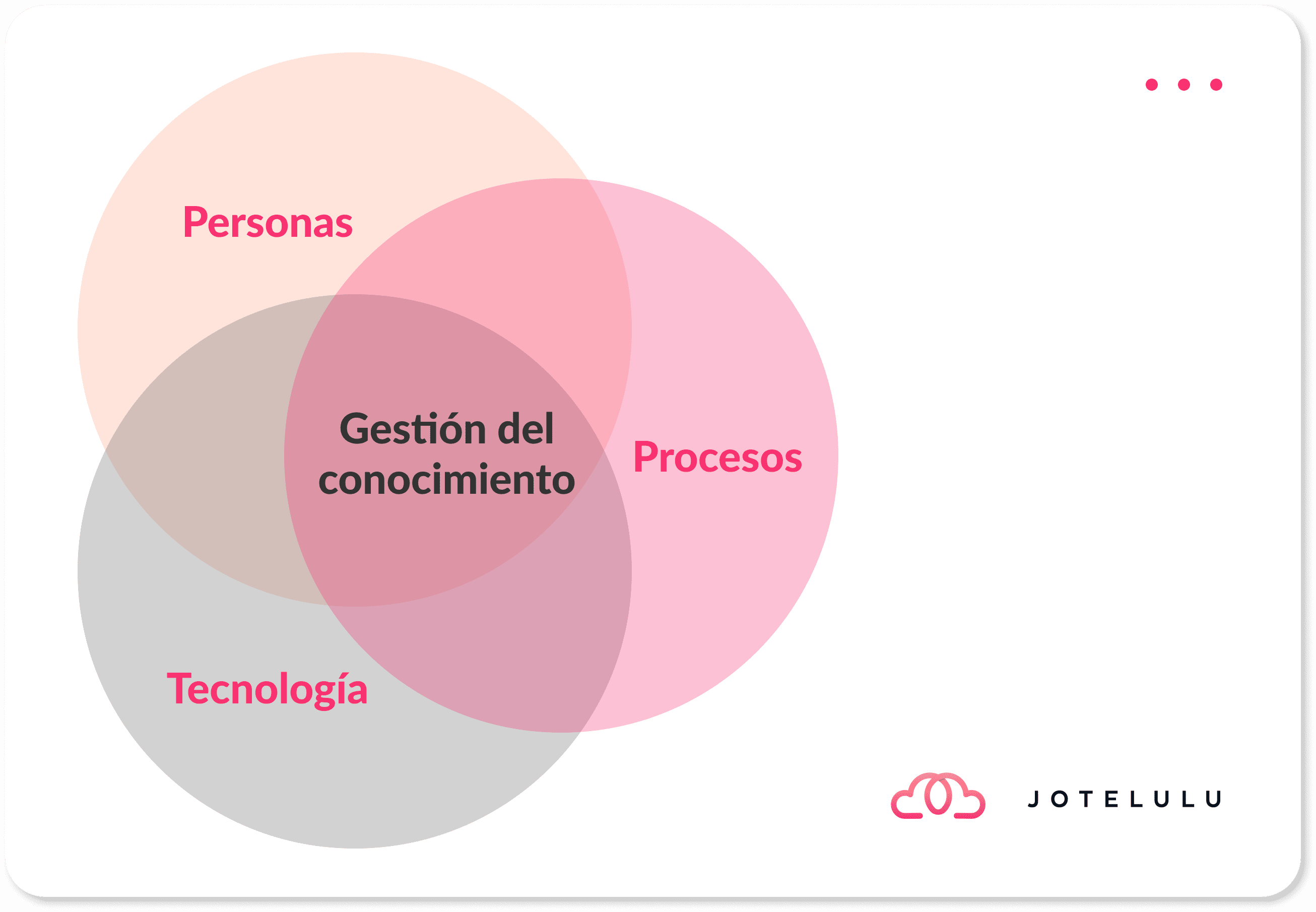
Imagen. Personas Procesos y Tecnología
Para empezar, se deben definir unos procedimientos claros, que no den cabida a la duda o al error y que ayuden a que el personal, bajo una situación de estrés como pueden ser la caída del servicio sea capaz de operar. Aquí entran todo tipo de procedimientos incluidos las cadenas de comunicación y notificación, los procedimientos de restore, workaround, etc.
Los procedimientos pueden ser de distinta índole, pero en casos como el Disaster Recovery suele ser de suma utilidad usar guías paso a paso con listas de verificación que pueden ser de dos tipos: la primera lista de verificación puede ser para la clasificación del tipo de medida se debe desencadenarse en función del evento que ha creado el incidente y el segundo tipo puede ser la clásica verificación realizada tras ejecutar el procedimiento.
Además de esto, se debe tener documentación detallada de todos los aspectos que rodean al plan de DR, incluyendo planes de respaldo y recuperación, procedimientos de escalado, configuraciones de hardware y software de los sistemas tanto habituales como de respaldo, los roles involucrados en la recuperación de desastres así como sus responsabilidades, y toda la documentación que pueda dar cobertura legal y de las normas asociadas al DR como ISO 27.001, ISO 22.301, ENS, Cobit, etc.
Estos últimos documentos son los de cumplimiento normativo que deberán ser creados para cumplir con esas regulaciones y estándares de la industria que apliquen en el territorio donde opere la organización.
Uno de los requerimientos normativos son los relativos a la seguridad de los datos de carácter personal, para los que habrá que asegurarse de que los datos estén siempre respaldados, que estén encriptados tanto en tránsito como en lugar donde se almacenan, y tener implementados controles de acceso adecuados para protegerlos frente a posibles ataques o exfiltraciones.
Tecnologías usadas frente a tecnologías adecuadas:
Las tecnologías usadas son determinantes a la hora de afrontar una recuperación de desastres, se deben valorar distintas herramientas y tecnologías en función del presupuesto, de las distintas legislaciones y normas que apliquen a la empresa, etc.
Por un lado, lo primero que debemos pensar es que modelo queremos usar en lo que respecta a la infraestructura de copias de seguridad y de replicación, se deben seleccionar tecnologías de almacenamiento y replicación que nos permitan realizar backups de manera eficiente de la misma manera nos permitan restaurar los datos de la manera más rápida posible.
Otro punto que se deberá valorar es el de la automatización, buscando la implementación de aquellas herramientas de automatización que, dentro de nuestro presupuesto, nos permitan la mejora de la eficiencia y una reducción de los errores, que por lo general van a ser de carácter humano.
Finalmente, y aunque el lector podrá suponer cual es nuestra apuesta en Jotelulu, la última decisión tecnológica que debemos tener en cuenta es si queremos hacer uso de soluciones basadas en on-prem o en la nube. Por supuesto, no solo podemos elegir soluciones de recuperación basadas en la nube y locales, sino que deberemos pensar en soluciones híbridas que puedan darnos un buen balance de disponibilidad y coste. Siempre se deberá considerar factores como el coste, la velocidad de recuperación y por supuesto, de manera transversal a todos los puntos, la seguridad.
Formación y concienciación:
Antes hemos hecho referencia a la terna “Personas Procesos y Tecnologías” y aquí vuelve a hacerse notar; la terna es tan importante que afecta a tres de los puntos tratados en este resumen de preocupaciones del DR.
En este sentido, es otro de esos puntos con los que soy tremendamente pesado, se debe tener formación o capacitación para el personal técnico que tenga que aplicar los procesos de DR para que de esta manera no sean meros autómatas ejecutando un procedimiento de DR sino que de esta manera nos aseguremos de que comprenden los roles y responsabilidades que deben ejercer en caso de producirse un desastre.
Por otro lado, para todo el personal sin excepción, sea este técnico o no, se debe establecer una política de concienciación que se centrará en fomentar una cultura de concienciación sobre la importancia de la recuperación ante desastres y la continuidad del negocio
Pruebas, operativas y validación:
Todo cuanto se haga dentro de un plan elaborado debe contener una serie de pruebas y de operativas encaminadas a la validación, por ello se deben establecer distintos elementos para el control de que todo está perfectamente planificado, creado y mantenido.
Se deben establecer pruebas regulares del plan de DR así como de cada una de sus partes de manera recurrente para, de esta manera, asegurarse de que todo funciona como está planificado y que todo el personal sabe como hacer su papel correctamente. Se deben hacer, siempre que se pueda, pruebas completas, pero dada la complejidad de esto, se pueden dividir distintos procesos que el personal vaya realizando continuamente para agilizar sus procesos. Este plan de pruebas debe incluir simulaciones de desastres y pruebas de restauración de datos.
Por otro lado, se debe verificar que los procedimientos de recuperación cumplen con los objetivos de RTO y RPO establecidos en la planificación, estableciendo así mismo un plan de documentación y corrección ante cualquier falla o ineficiencia detectada durante las pruebas.
Por último, se deben implementar sistemas de monitorización para detectar fallos o problemas en la infraestructura de DR y de esta manera asegúranos de que se notifiquen y se resuelvan rápidamente.
Mejora continua del Disaster Recovery:
No quiero ser pesado con esta parte, que creo que lo digo en todas partes y en todos los artículos en los que hablamos de sistemas o de seguridad; la obligación de todo administrador, todo técnico y todo responsable de un servicio es conseguir que las cosas estén cada día mejor, “el que no evoluciona se extingue” y esto es una máxima que, si sirvió para los dinosaurios, que vivían en un mundo mucho menos cambiante, imagínense como de válido es para nosotros.
Se deben sopesar nuevos riesgos continuamente, tomar lecciones aprendidas y proponer mejoras de manera continuada, se deben plantear cambios en los sistemas, actualizarlos, etc.
Sin duda, se debe vivir en una retrospectiva continua, en la que nos preguntamos ¿qué está bien? ¿Qué puede mejorarse? ¿Qué debe cambiar? Y a partir de ahí empezar a trabajar en planes de mejora.
Al final, trabajamos en un modelo basado en Ciclo de Deming en el cual siempre estaremos en una de las fases del famoso:
- Plan.
- Do.
- Check.
- Act.
Conclusiones:
Tal como hemos visto en el artículo, los 10 principales preocupaciones al montar un Disaster Recovery en una pyme son simples de comprender y están compartidas por casi todos nosotros, ya que nos jugamos la supervivencia de nuestros negocios, pero son igualmente afrontables si logramos elaborar un buen plan de implementación y mantenimiento, como siempre, recalcaré que necesitamos el apoyo de la dirección y de planificar e invertir tiempo para pensar seriamente en las necesidades, en el plan de implementación, etc. para, de esta manera, estar preparados cuando los problemas que hagan necesarios tener el plan funcionando lleguen.
Si quieres aprender más sobre seguridad te recomendamos echar un ojo a estos otros artículos de nuestro blog.
- Pasos para gestionar un incidente de seguridad en IT
- Cuál es el coste real de no invertir en seguridad
- Problemas típicos de los backups
- Estrategia 3, 2, 1 de Backup
- Las 5 principales causas de pérdida de datos en la pyme
- Cómo evaluar riesgos y amenazas en la pyme
- Por qué el Disaster Recovery es tan doloroso
¡Gracias por acompañarnos!
29 de mayo de 2024