Sigue leyendo si quieres descubrir cómo montar un entorno de Kubernetes en Jotelulu y sacarle todo su jugo.
Desde que Google liberó el proyecto de Kubernetes hace casi 10 años (2014), esta tecnología ha ido adquiriendo más y más notoriedad, hasta que se ha hecho un elemento imprescindible en la gestión de microservicios.
Kubernetes es una plataforma extensible, portable y flexible basada en open software (código abierto) que nos permite administrar cargas de trabajo de distintos tamaños y que incluye el tamaño variable, permitiendo desplegar todo tipo de servicios, facilitando entre otras cosas la automatización y la respuesta a picos de trabajo y otros tipos de cargas de trabajo cambiantes.
La forma de operación de Kubernetes hace que sea una plataforma ideal para gestión basada en PaaS (Plataformas como Servicio) o IaaS (Infraestructura como Servicio).
¿Cómo montar un entorno de Kubernetes en Jotelulu?
Pre-requisitos y recomendaciones:
Para completar de forma satisfactoria este tutorial y poder montar un entorno de Kubernetes en Jotelulu será necesario:
- Por un lado, estar dado de alta en la Plataforma Jotelulu con una organización y estar registrado en la misma tras hacer Log-in.
- Por otro lado, haber dado de alta una suscripción de Servidores.
- Tener tres servidores Ubuntu 22.04 desplegados dentro de la suscripción.
-
- kubernetes-nacho-1 = Máster.
- kubernetes-nacho-2 = Worker 1.
- kubernetes-nacho-3 = Worker 2.
- Un usuario con privilegios de administrador o bien a través de “root” o mediante el comando “sudo”.
- Según las especificaciones de Kubernetes, las máquinas virtuales provisionadas deben tener al menos 2GB de RAM, 2 CPUs y al menos 20GB de disco duro para poder trabajar, aunque en función del uso que se les vaya a dar puede ser necesario incrementar estos requerimientos.
Paso 1. Preparando la máquina antes del despliegue de Kubernetes
Lo primero que se deberá hacer antes de empezar con el despliegue de Kubernetes es actualizar los paquetes y la distribución para asegurarnos de que contamos con los paquetes más actualizados y las últimas fuentes actualizadas.
Para ello se deben lanzar los siguientes comandos.
# sudo apt update
# sudo apt upgrade
Recordemos que el comando “sudo” se usa en las distribuciones Ubuntu para lanzar los comandos con una elevación de privilegios. Sería algo así como un “Super User Do” (Hacer como Super Usuario), es el equivalente a un “RunAs” en entornos de Microsoft.
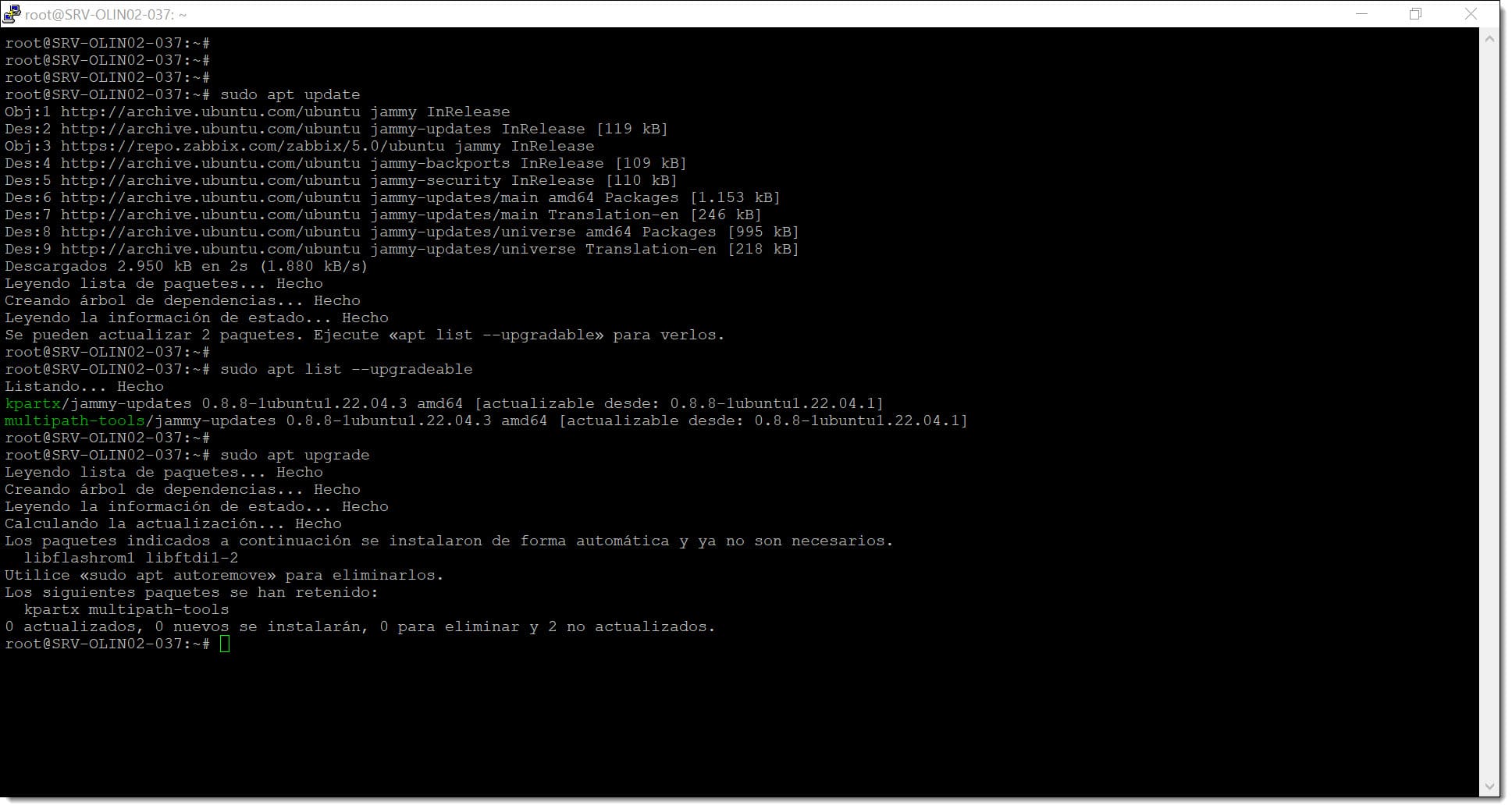
Paso 1. Lanzamos la actualización de los paquetes y de la distribución
Uno de los puntos que debemos controlar cuando trabajemos con Kubernetes es el uso de la memoria de intercambio o SWAP. En ocasiones se han producido problemas durante el escalado de los PODS, ya que el sistema no los gestiona correctamente en caso de tener activa la SWAP del sistema.
Para evitar comportamientos erráticos, la mejor opción es deshabilitar dicha opción usando el comando “swapoff”.
# sudo swapoff -a
Para comprobar si se ha deshabilitado, se pueden usar varios métodos.
# free -h
# swapon -s
# cat /proc/swaps
Para que no se active en el reinicio y no se pueda usar de ninguna manera se debe eliminar de la tabla de sistemas de ficheros, o sea de “/etc/fstab” por lo que se debe editar y comentar las líneas donde aparezca la palabra “swap”.
# sudo vim /etc/fstab
Una vez hecho se pueda hacer la consulta con un “cat” (si eres un defensor de los gatos puedes usar cualquier otro comando de visualización) para ver si está correctamente salvado.
# cat /etc/fstab
Este proceso de limpieza del fichero “/etc/fstab” también podríamos hacerlo mediante el siguiente comando:
# sudo sed -i ‘/ swap / s/^/#/’ /etc/fstab
Este comando basado en “sed” busca la cadena “swap”, sin aplicar tipado y hace sitúa una almohadilla “#” que es el símbolo usado para comentar texto.
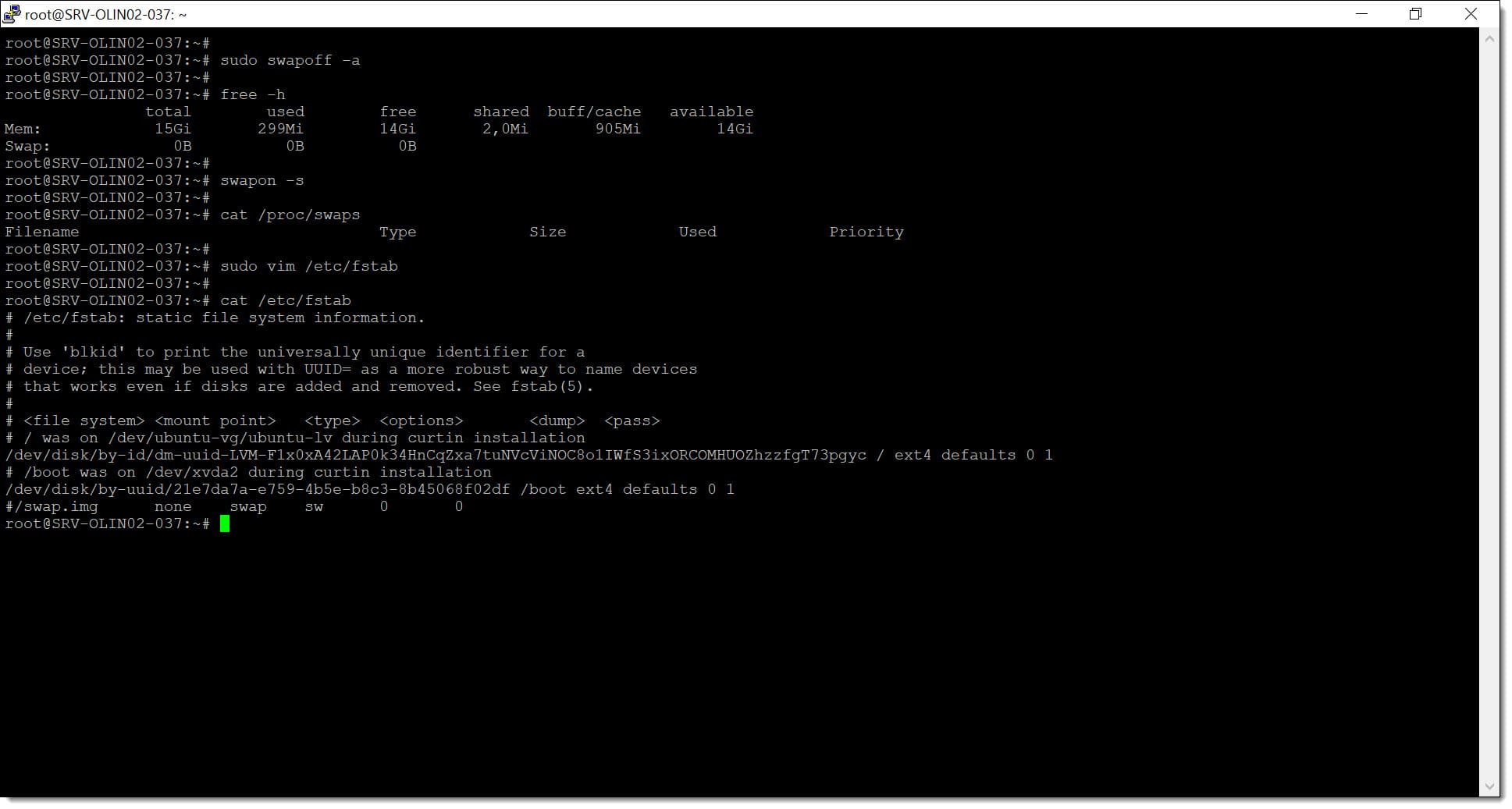
Paso 1. Deshabilitamos la SWAP para que no haya problemas con los PODS de Kubernetes
Es posible que se desee cambiar el nombre de la máquina para identificarlo dentro de nuestra red o por cualquier otro propósito. Este proceso se puede realizar antes de todo el proceso de levantar los Kubernetes, motivo por el que lo comentamos antes de empezar con la operativa en sí.
Se consulta el nombre actual mediante el comando “hostname”, aunque realmente debería ser visible como parte del prompt de Bash.
# hostname
A continuación, para cambiar el nombre de la máquina se lanza el comando “sudo hostnamectl set-hostname” seguido por el nuevo nombre y se lanza el comando “exec bash” para que los cambios tomen efecto.
Un ejemplo de todo esto podría ser:
# sudo hostnamectl set-hostname <Nuevo_Nombre>
# exec bash
Donde:
- <Nuevo_Nombre>: Será el nombre que reciba la máquina desde ese momento.
Un ejemplo podría ser:
# sudo hostnamectl set-hostname kubernetes-nacho-1
# exec bash
Donde:
- “kubernetes-nacho-1” será el nombre que reciba la máquina desde ese momento.
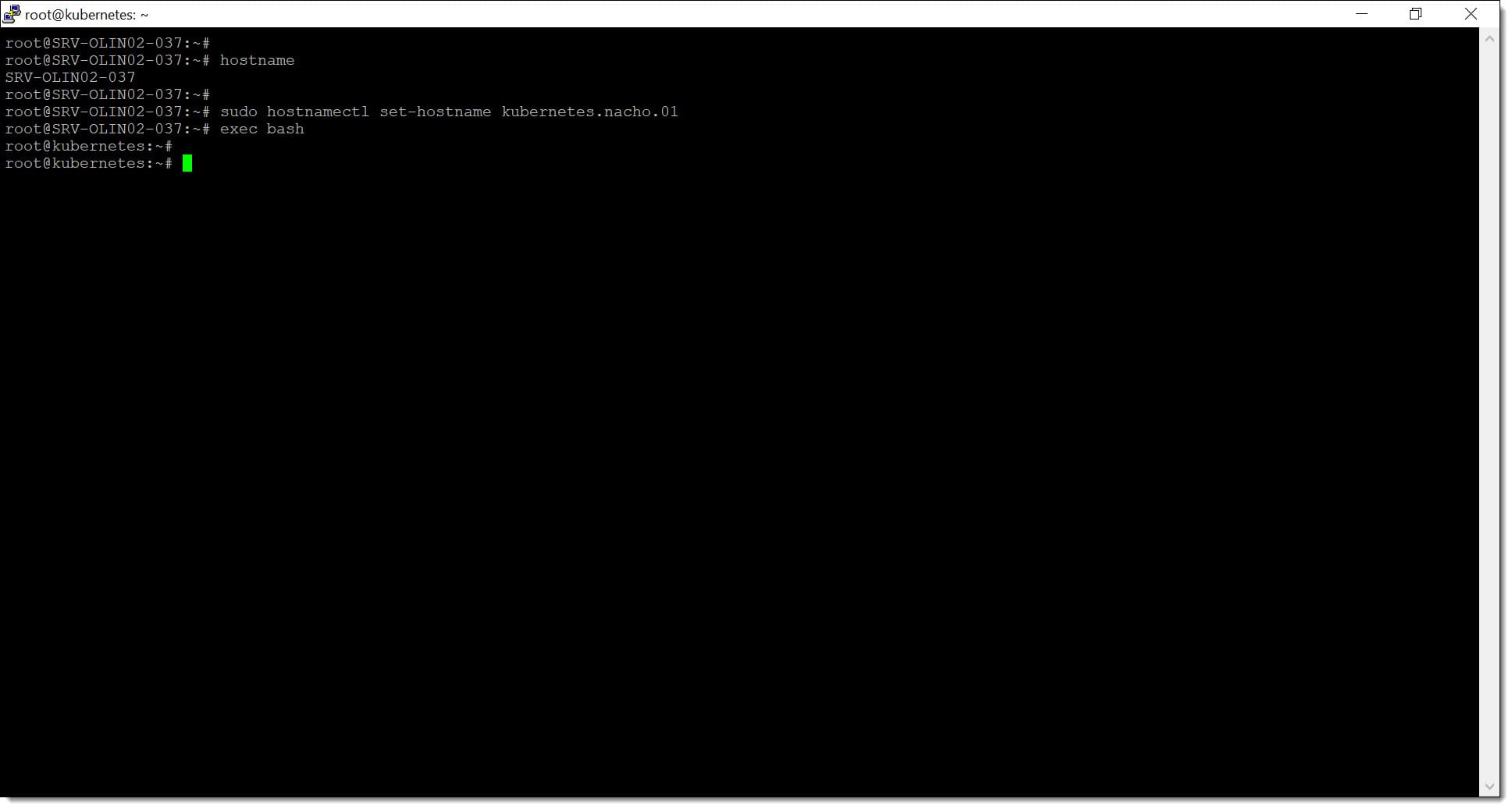
Paso 1. Cambiamos el nombre de la máquina para identificarla en la red como servidor de Kubernetes
El siguiente paso es configurar el kernel (núcleo del sistema) con unos parámetros adicionales para que Kubernetes pueda trabajar correctamente.
Para ello se debe editar el fichero “/etc/sysctl.conf” ejecutando los siguientes comandos:
# sudo tee /etc/modules-load.d/containerd.conf <<EOF
overlay
br_netfilter
EOF
# sudo modprobe overlay
# sudo modprobe br_netfilter
Y la siguiente secuencia:
# sudo tee /etc/sysctl.d/99-kubernetes-cri.conf <<EOF
net.bridge.bridge-nf-call-iptables = 1
net.bridge.bridge-nf-call-ip6tables = 1
net.ipv4.ip_forward = 1
EOF
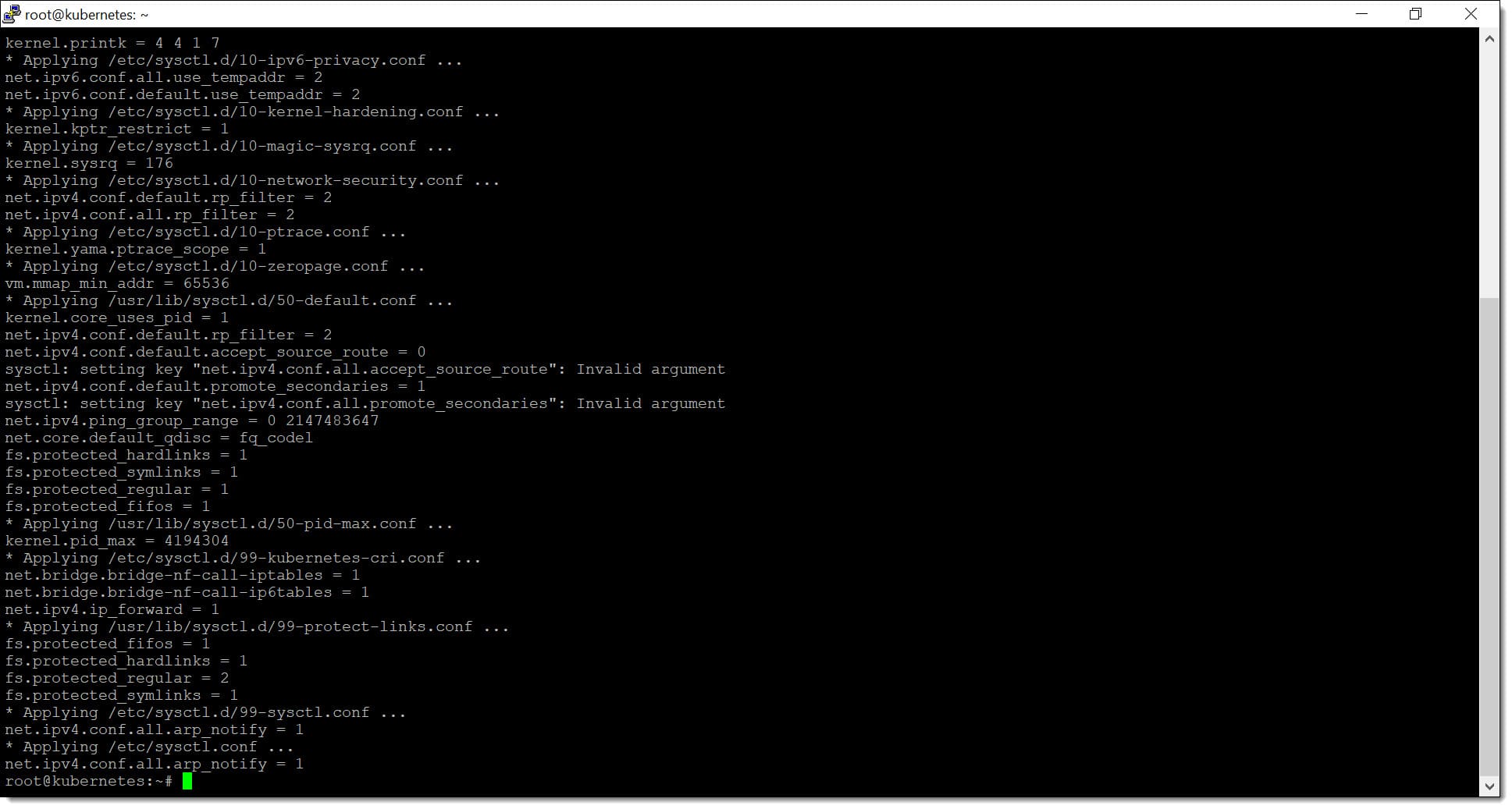
Paso 1. Configuramos parámetros del Kernel para el uso de Kubernetes
El siguiente paso será lanzar el comando “sysctl –system” para que recargue la configuración del núcleo con los cambios que hemos hecho.
# sudo sysctl –system
Deberemos revisar la arquitectura que queremos montar y las IPs y nombres que tienen los servidores implicados, que en este caso sería algo así:
| Servidor | Nombre en Jotelulu | IP Interna |
| kubernetes-nacho-1 | Ubuntu22Nacho1 | 10.0.0.96 |
| kubernetes-nacho-2 | Ubuntu22Nacho2 | 10.0.0.33 |
| kubernetes-nacho-3 | Ubuntu22Nacho3 | 10.0.0.92 |
Con lo que generamos los datos que debe contener el fichero “/etc/hosts”, que debería ser:
10.0.0.96: kubernetes-nacho-1
10.0.0.33: kubernetes-nacho-2
10.0.0.92: kubernetes-nacho-3
Paso 2. Instalando Kubernetes en nuestro sistema Ubuntu
En este punto se va a empezar con la configuración de Kubernetes propiamente dicha, por lo que se deben descargar e instalar los paquetes de manera segura. Para ello se vuelve a usar el comando “apt” añadiendo el uso de certificados.
# sudo apt-get install -y apt-transport-https ca-certificates curl
Paso 2. Aseguramos la descarga e instalación de los paquetes de manera segura
Para la correcta operación de Kubernetes, se debe crear un directorio en el que se verificará la autenticidad de los paquetes de Kubernetes.
# sudo mkdir /etc/apt/keyrings
En este punto se debe buscar la clave pública y almacenarla en la carpeta que se acaba de crear. De esta manera, los paquetes de Kubernetes serán validados para evitar que nos den gato por liebre y tener claro que todos los paquetes sean legítimos.
# curl -fsSL https://packages.cloud.google.com/apt/doc/apt-key.gpg | sudo gpg –dearmor -o /etc/apt/keyrings/kubernetes-archive-keyring.gpg
Se añade la fuente de descarga de Kubernetes.
# echo «deb [signed-by=/etc/apt/keyrings/kubernetes-archive-keyring.gpg] https://apt.kubernetes.io/ kubernetes-xenial main» | sudo tee /etc/apt/sources.list.d/kubernetes.list
Actualicemos el índice del paquete “apt” para ver nuevos elementos ejecutando el comando “sudo apt-get update” nuevamente.
# sudo apt-get update
A continuación se deben instalar los paquetes kubelet, kubeadm y kubectl ejecutando el comando “apt install” con las distintas versiones de Kubernetes.
A modo informativo vamos a decir para qué sirve cada uno de los paquetes kubelet, kubeadm y kubectl.
- Kubelet: Es el servicio que se ejecuta en todos los nodos pertenecientes al clúster de Kubernetes y es responsable de ejecutar los PODS y los contenedores.
- Kubeadm: Se usa para generar el clúster de Kubernetes.
- Kubectl: Se usa para la operación diaria del clúster de Kubernetes.
El comando a la lanzar es el siguiente, aunque puede haber variaciones debidas a los cambios de versión:
# sudo apt install -y kubelet=1.26.5-00 kubeadm=1.26.5-00 kubectl=1.26.5-00 command.
NOTA: En caso de fallar, es posible que se necesite añadir el comando para añadir “–allow-downgrades”.
# sudo apt install -y –allow-downgrades kubelet=1.26.5-00 kubeadm=1.26.5-00 kubectl=1.26.5-00

Paso 2. Lanzamos la instalación de los paquetes de Kubernetes en Ubuntu
El siguiente punto es desplegar Docker para dar servicio a Kubernetes. Docker será la plataforma seleccionada para la creación de los contenedores que emplee Kubernetes, esta nos permitirá crear, distribuir y ejecutar aplicaciones dentro de contenedores de manera sencilla.
El motivo por el que se usan contenedores y no máquinas virtuales es porque estos nos ofrecen un entorno mucho más ligero, portable y elástico, garantizando de esta manera un mayor rendimiento en sus distintas configuraciones.
NOTA: Ya hemos hablado previamente de Docker en nuestro Blog, con artículos como Cómo montar un Docker en Jotelulu o Cómo instalar Odoo en un servidor Linux de Jotelulu
Para la instalación usamos el comando “sudo apt install docker.io” que realiza la instalación del paquete de Docker.
# sudo apt install docker.io
Paso 2. Instalamos Docker para dar servicio a Kubernetes
El siguiente punto es la configuración de “Containerd” en todos los nodos del clúster para garantizar su compatibilidad con Kubernetes.
Para ello, lo primero que se debe hacer es crear una carpeta para el archivo de configuración.
# sudo mkdir /etc/containerd
Una vez hecho esto se debe crear un archivo de configuración predeterminado para containerd y guardarlo con el nombre “config.toml”.
# sudo sh -c «containerd config default > /etc/containerd/config.toml».
Después de ejecutar estos comandos, se deberá modificar el archivo “config.toml” para localizar la entrada que establece «SystemdCgroup = false” y cambia su valor «SystemdCgroup = true”.
# sudo sed -i ‘s/ SystemdCgroup = false/ SystemdCgroup = true/’ /etc/containerd/config.toml
Para terminar esta parte se deben reiniciar los servicios de “contenedord” y “kubelet” ya que de esta manera se releerá la configuración y se guardaran los cambios.
# sudo systemctl restart containerd.service
# sudo systemctl restart kubelet.service
Lo normal es que se quiera iniciar Kubernetes y por tanto el servicio Kubelet cada vez que se inicie la máquina, por lo que se deberá ejecutar el siguiente comando:
# sudo systemctl enable kubelet.service.
Paso 2. Preparamos el sistema para el uso de Containered
El siguiente paso es arrancar el clúster de Kubernetes en el nodo maestro, con lo que cuando se arranque un plano de control de Kubernetes mediante kubeadm, se implementarán distintos componentes para administrar y orquestar el clúster.
Con el siguiente comando se descargarán las imágenes de los componentes (kube-apiserver, kube-controller-manager, kube-scheduler, etcd, kube-proxy).
# sudo kubeadm config images pull
Inicializamos el nodo maestro pasándole “–pod-network-cidr” con el rango de direcciones IP que tenemos resevados para la red de POD.
# sudo kubeadm init –pod-network-cidr=10.0.0.0/16
Paso 2. Arrancamos el clúster de Kubernetes
En este punto se va a configurar kubectl, que es la herramienta con la que se debe administrar el clúster de Kubernetes. Para ello se debe empezar por crear el el directorio .kube en el HOME y copiar la configuración de administración del clúster.
# mkdir -p $HOME/.kube
# sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
Tras esto se deberá cambiar la propiedad del archivo de configuración que se ha copiado para darle permiso al usuario para hacer uso del archivo de configuración.
# sudo chown $(id -u):$(id -g) $HOME/.kube/config
A continuación se van a configurar tanto kubectl como Calico, que serán necesarios para la operación de nuestro servicio de Kubernetes. Para ello será necesario ejecutar los siguientes comandos en el nodo máster de manera que se implemente el operador Calico.
# kubectl create -f https://raw.githubusercontent.com/projectcalico/calico/v3.26.1/manifests/tigera-operator.yaml
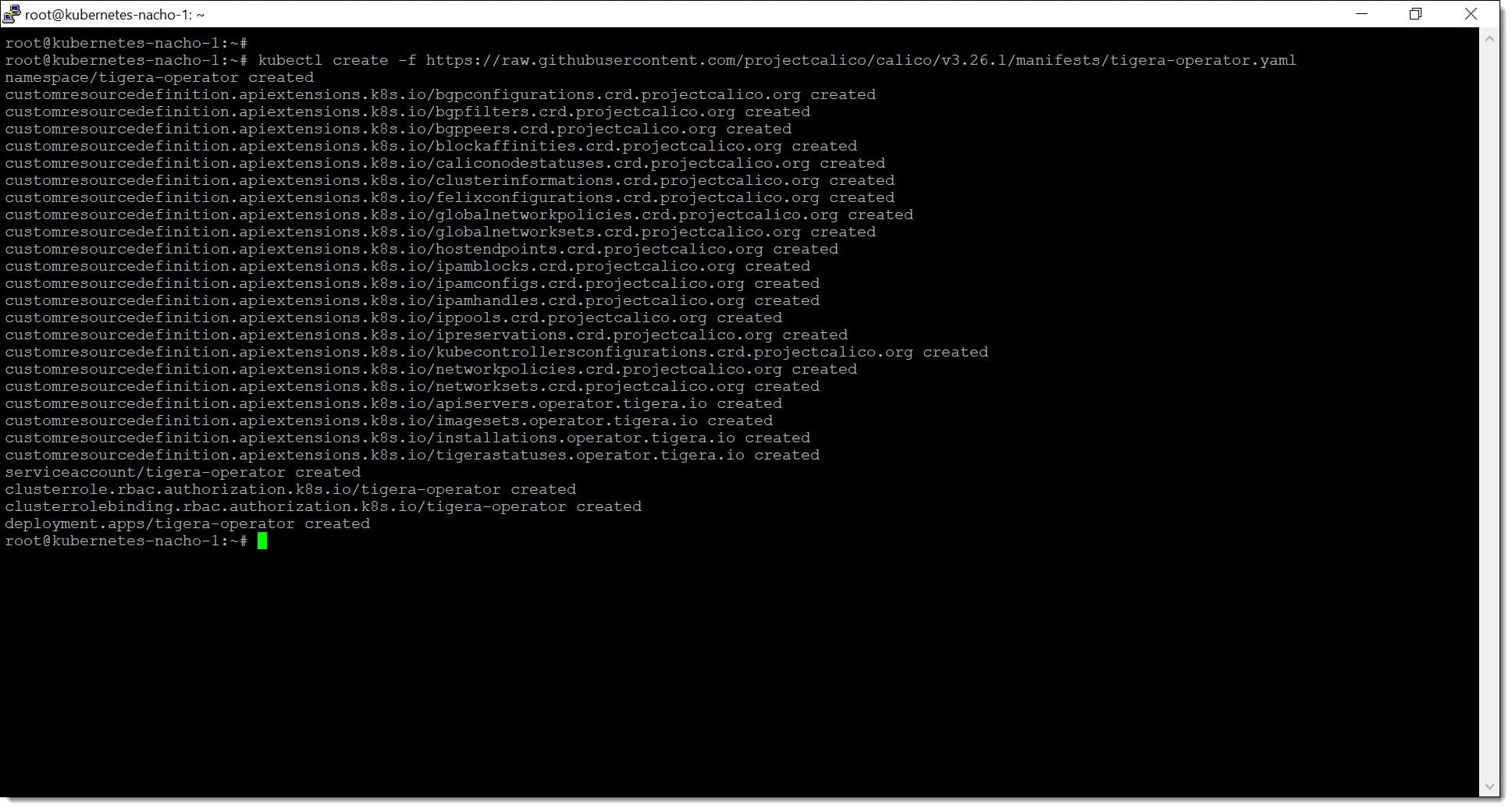
Paso 2. Configuramos Kubctl y Calico en nuestra Ubuntu
El siguiente paso que se debe dar es el de descargar el archivo de recursos personalizados para Calico, que contiene distintas configuraciones necesarias para el uso de este servicio.
# curl https://raw.githubusercontent.com/projectcalico/calico/v3.26.1/manifests/custom-resources.yaml -O
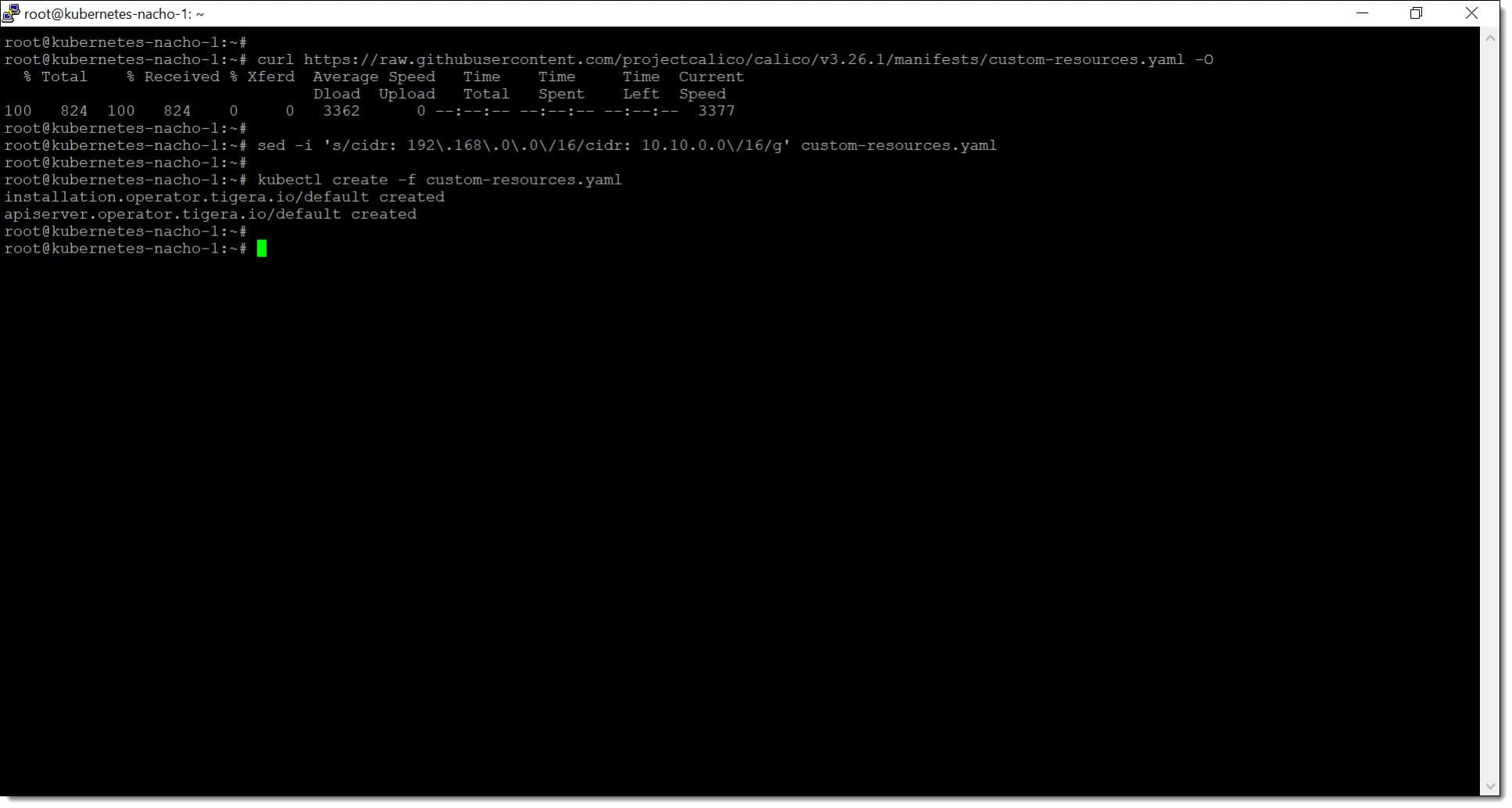
Paso 2. Descargamos los recursos de Calico y configuramos el CDIR de nuestro clúster de Kubernetes
En este punto se debe modificar el CIDR en el fichero de configuración “custom-resources.yaml” para que los recursos coincidan con la red de POD que se va a provisionar en nuestro caso.
# sed -i ‘s/cidr: 192\.168\.0\.0\/16/cidr: 10.0.0.0\/16/g’ custom-resources.yaml
En este momento se le dice a kubectl que lea el contenido del archivo “custom-resources.yaml” y que cree los recursos definidos en ese archivo, para lo que se debe lanzar el siguiente comando:
# kubectl create -f custom-resources.yaml
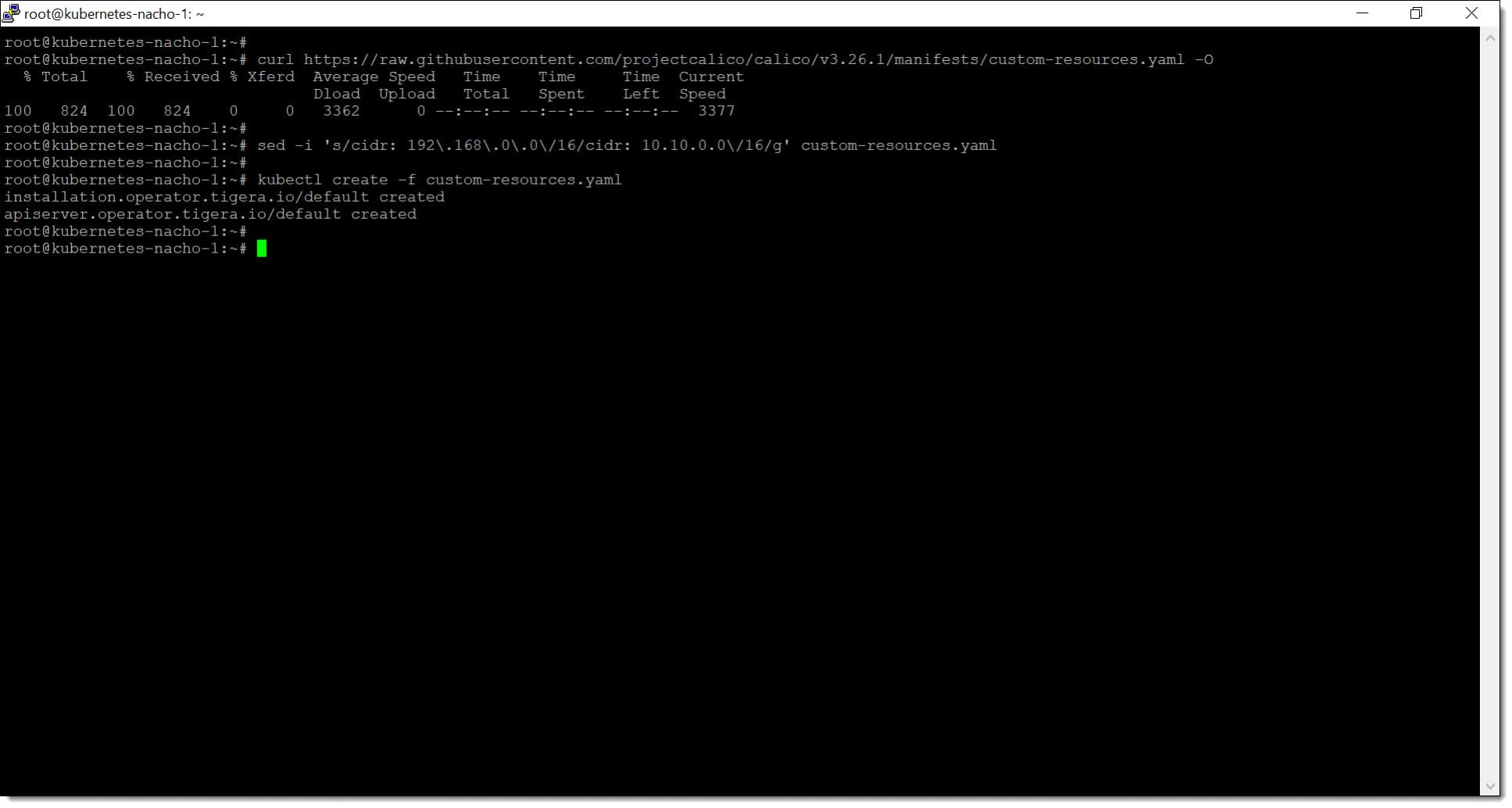
Paso 2. Configuramos el CDIR de nuestro clúster de Kubernetes
Con esto ya debería estar todo configurado dentro de nuestro máster, por lo que pasamos a configurar los workers.
Paso 3. Añadir workers al clúster de Kubernetes
Ahora que se tiene configurado el nodo máster de nuestro clúster de Kubernetes es tiempo de agregar los nodos workers al clúster que serán los que realicen el trabajo real, dejando al máster la tarea de coordinar.
Cuando se inicie el Kubeadm del nodo máster se proporcionará un token que será usado para la adición de esos nodos de trabajo, que serán añadidos mediante el comando “kubeadm join”.
# sudo kubeadm join <IP_NODO_MASTER >:<PUERTO_API_SERVER> –token <TOKEN> –discovery-token-ca-cert-hash <HASH_CERTIFICADO>
Donde:
- <IP_NODO_MASTER>: Dirección IP del nodo máster del clúster de Kubernetes.
- <PUERTO_API_SERVER>: Puerto de comunicación, normalmente el “6443”.
- <TOKEN>: Pasamos el token de validación.
- <HASH_CERTIFICADO>: Pasamos el HASH del token para poder hacer las comprobaciones matemáticas.
Con esto ya habríamos sumado los workers a la estructura de Kubernetes y podremos empezar a operar la plataforma.
NOTA: En caso de encontrar algún problema durante este procedimiento, se puede consultar la ayuda a la instalación de Kubernetes.
Conclusiones:
Como puedes ver, montar un entorno de Kubernetes en Jotelulu es algo muy sencillo de hacer siguiendo los pasos que hemos descrito.
En este caso hemos visto cómo desplegar el servicio de Kubernetes en nuestros servidores GNU/Linux, Ubuntu 22.04 (la última versión disponible a esta fecha) pero puede usarse el mismo procedimiento para otras versiones aplicando ligeros cambios.
Puedes revisar otros tutoriales y artículos relacionados con esta tecnología, de GNU/Linux u otras tecnologías revisando nuestro blog.
¡Gracias por acompañarnos!