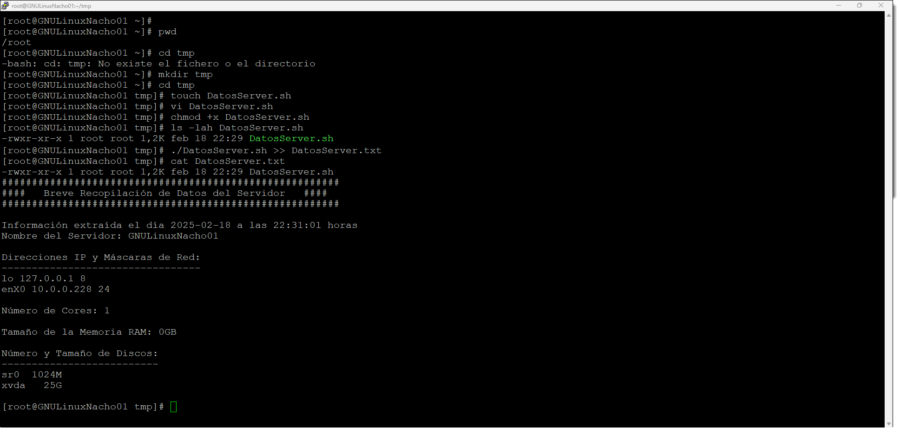
Cómo hacer la recopilación de datos básicos para Migraciones de GNU/Linux
Cómo hacer la recopilación de datos básicos para Migraciones de GNU/Linux
Escrito por
Categorías
Migraciones
Servidores