








Cloud y sistemas
Disaster Recovery: Qué son RPO, RTO, WRT o MTD y por qué son importantes
14 de febrero de 2024
Hablemos de Disaster Recovery: ¿qué son RPO, RTO, MTD o WRT y por qué es importante comprender estos conceptos si hablamos de continuidad de negocio, continuidad de servicio y recuperación frente a desastres?
En ocasiones, cuando se habla de recuperación frente a desastres (Disaster Recovery), o impactos en el servicio o en el negocio, muchos nos asustamos porque se empieza a hablar de siglas y acrónimos que parecen ser creados para espantar a los neófitos y profanos.
En este artículo pretendemos empezar a apartar la neblina de misterio arcano que envuelve todos estos conceptos relacionados con el Disaster Recovery para ayudarte a andar en el buen camino y asegurar la continuidad de tu negocio pase lo que pase.
Supongamos que nos encontramos en una empresa en la que tenemos una operación normal, sin grandes problemas de funcionamiento ni nada similar, como sería la operación de la mayoría de las organizaciones que todos conocemos: habría algún PC con virus que genera un pequeño problema, otro ordenador al que le cambiamos el ratón porque falla, una impresora que da problemas hasta que cambiamos el tóner y deja de fallar… En fin, lo normal en una empresa.
Esto sería lo que se llama la operación normal de los sistemas, en los cuales no hay una interrupción del servicio ni se pone en peligro la continuidad de la empresa ni nada similar.
En este momento estaríamos en una situación como se muestra en la gráfica.

Imagen. Operación correcta de los servicios
Pasado un tiempo, en el que el servicio opera sin problemas, se produce una caída del servicio.
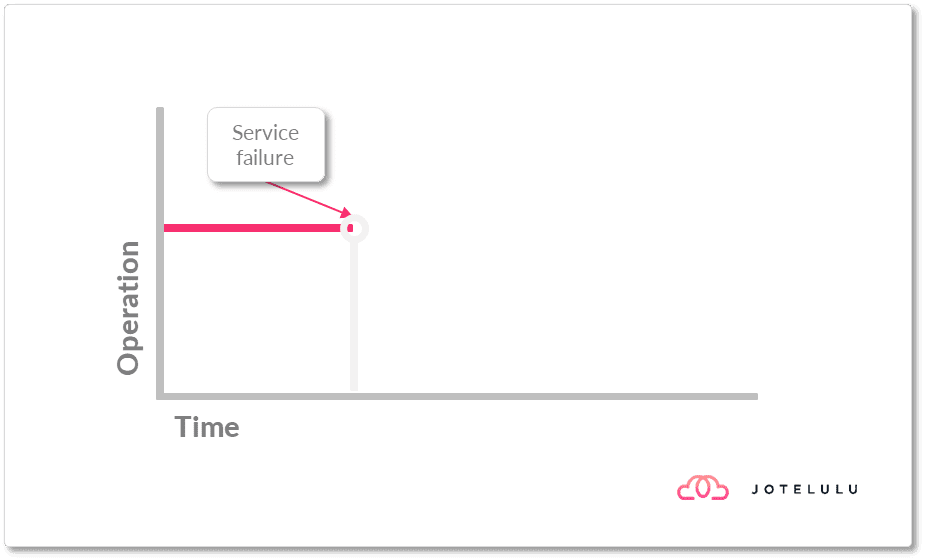
Imagen. Se produce la caída del servicio
Cuando esto sucede y se presenta un desastre, como es lógico, es necesario reestablecer el correcto funcionamiento de los sistemas y la correcta operación de la empresa lo antes posible.
En este punto, además, se suele describir el RPO (Recovery Point Objective u Objetivo de Punto de Recuperación) que establece básicamente la cantidad máxima de pérdida de datos o de pérdida de servicio medida en el tiempo que es aceptable para nuestro negocio.
Este valor de RPO puede variar drásticamente en función del servicio afectado y del tipo de negocio al que nos dediquemos, así como de otros parámetros como pueda ser el horario en el que se impacta.
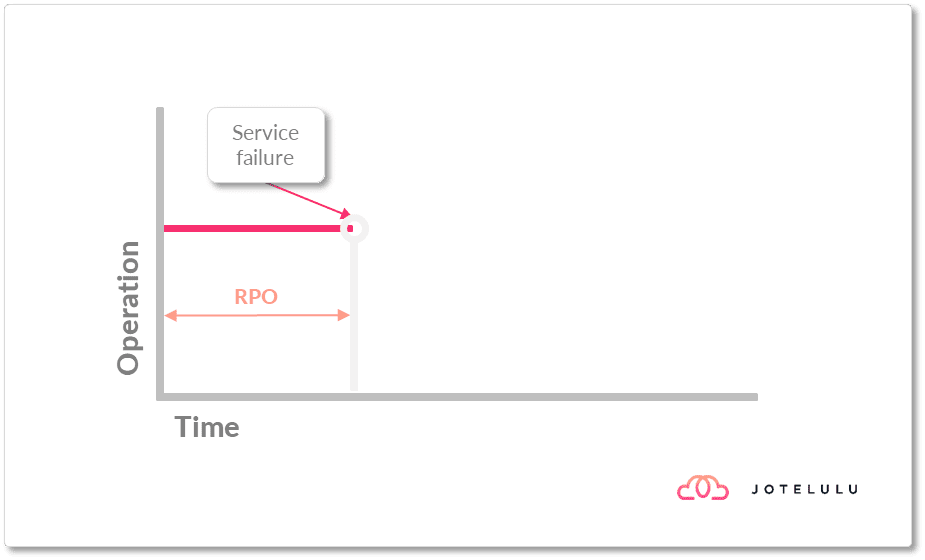
Imagen. Introducimos el RPO
Cuando hablamos del proceso de recuperación, hablamos del proceso desde que se detecta que el sistema o servicio está caído y se empieza a intervenir sobre él, hasta que pasa a estar operativo. Durante este tiempo el servicio no se ha recuperado aún, por lo que aún no se puede considerar como un servicio productivo, o sea, que dé servicio normal.
El RTO (Recovery Time Objective u Objetivo de Tiempo de Recuperación) determina el tiempo máximo que será tolerable que un servicio crítico pueda volver a dar servicio.
Dentro de esta operativa están incluidas las acciones para levantar la arquitectura pertinente, ponerla en funcionamiento y recuperar los datos que permitirán operarla de manera correcta.
Un ejemplo de esto podría ser la caída del servidor que hospeda la base de datos de nuestro ERP, en la que se debe levantar un nuevo servidor, desplegar la base de datos y recuperar la base de datos antes de poder recuperar el servicio en producción.
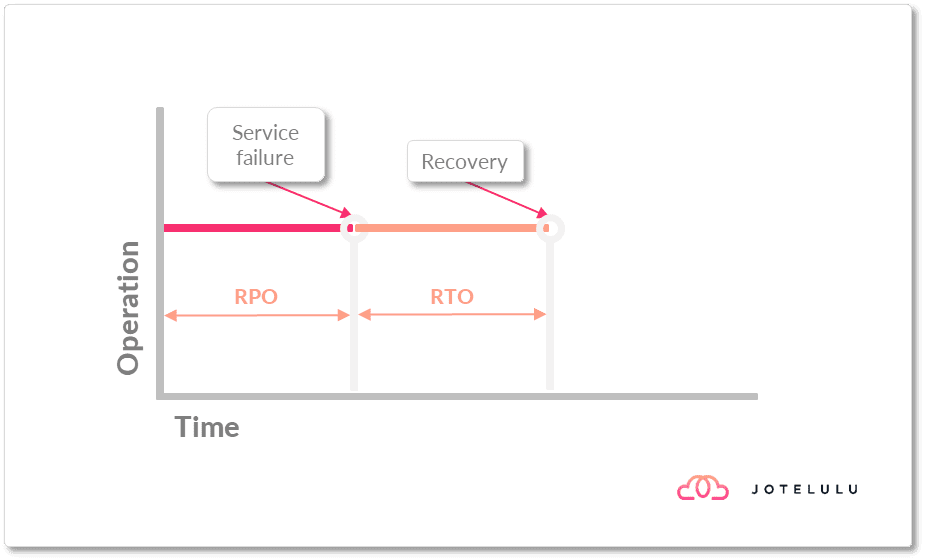
Imagen. Introducimos el RTO
Pero aún no hemos puesto en producción el servicio, simplemente lo hemos levantado, pero no está dando servicio a nuestros clientes o empleados, por lo que el contador sigue corriendo en nuestra contra y seguimos perdiendo dinero.
En este punto tenemos el WRT (Work Recovery Time o Tiempo de Recuperación del Trabajo), que es el tiempo en el que se recuperará el servicio real mediante la verificación de los sistemas y la puesta en línea de estos tras haberlos recuperado en la parte de RTO.
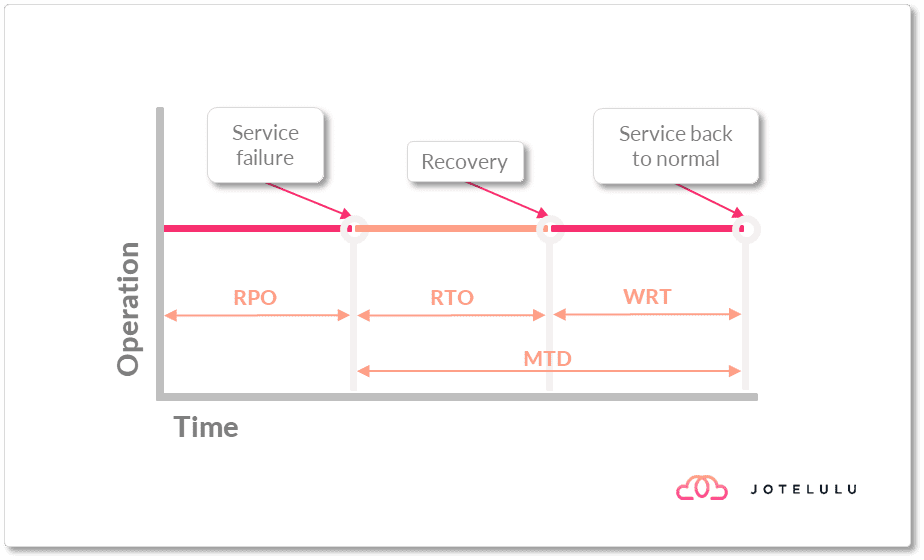
Imagen. Introducimos el WRT
En este caso, la suma del RTO más WRT es lo que se llama MTD (Maximum Tolerable Downtime o Tiempo de Inactividad Máximo Tolerable), que básicamente describe el tiempo máximo que puede estar inoperativo el servicio antes de que las consecuencias sean inaceptables para la empresa.
Lo que estamos introduciendo aquí son, de manera muy sencilla, los fundamentos del Disaster Recovery, pero si quisiéramos trabajar un plan de continuidad de negocio o de recuperación ante desastres deberíamos calcular los valores y tener muy claro cuánto puede aguantar cada uno de los servicios de nuestra organización y cómo podemos optimizar todo para que no haya problemas y aseguremos la supervivencia.
Esperamos que lo que has leído en este artículo te haya ayudado a entender qué son RPO, RTO, MTD o WRT y por qué es importante comprender estos conceptos para la supervivencia de tu negocio.
Te animamos a seguir leyendo otros artículos de esta colección que podrás encontrar en nuestro blog.