








Cloud y sistemas
Cómo eliminar líneas en blanco mediante un script GNU/Linux
14 de agosto de 2023
Acompáñanos a lo largo de este breve artículo donde descubriremos cómo eliminar líneas en blanco mediante un script GNU/Linux.
AWK es uno de los lenguajes de programación más usados en el mundo UNIX para el procesamiento de texto, y es uno de los recursos obligatorios que se deben dominar cuando se está dentro de este mundo.
El nombre está compuesto por las iniciales de sus creadores, que sin duda conocerás de otros proyectos, al menos si estás familiarizado con el mundo UNIX y el del software libre:
AWK se suele usar junto a SED, un editor de línea de comandos que recibe su nombre de su capacidad de trabajar como editor en línea, ya que sería su traducción directa al inglés “stream editor”.
SED permite realizar operaciones de edición con datos extraídos de archivos o desde la entrada de datos estándar (standard input o stin). Otro de los puntos a destacar es que se trabaja en modo no interactivo.
La potencia de ambas herramientas se multiplica cuando se usan ambas en conjunción, ya que
Como curiosidad, AWK y SED son la fuente original de inspiración para la creación de uno de los lenguajes de scripting más potentes y ampliamente usados: Perl, ya que Larry Wall se fundamentó en estos para la creación de su potente lenguaje de programación, del que me declaro acérrimo fan, aunque he de reconocer que un fan bastante torpe.
Para encontrar el número de líneas en blanco en un archivo, usa el siguiente comando:
# cat <fichero_origen> |awk ‘/^$/ { ++x } END { print «Numero de lineas en blanco = » x }’
Donde:
Un ejemplo de esta ejecución podría ser:
# cat ficheroprueba.txt |awk ‘/^$/ { ++x } END { print «Numero de lineas en blanco = » x }’
Tal como podemos ver en la siguiente captura.
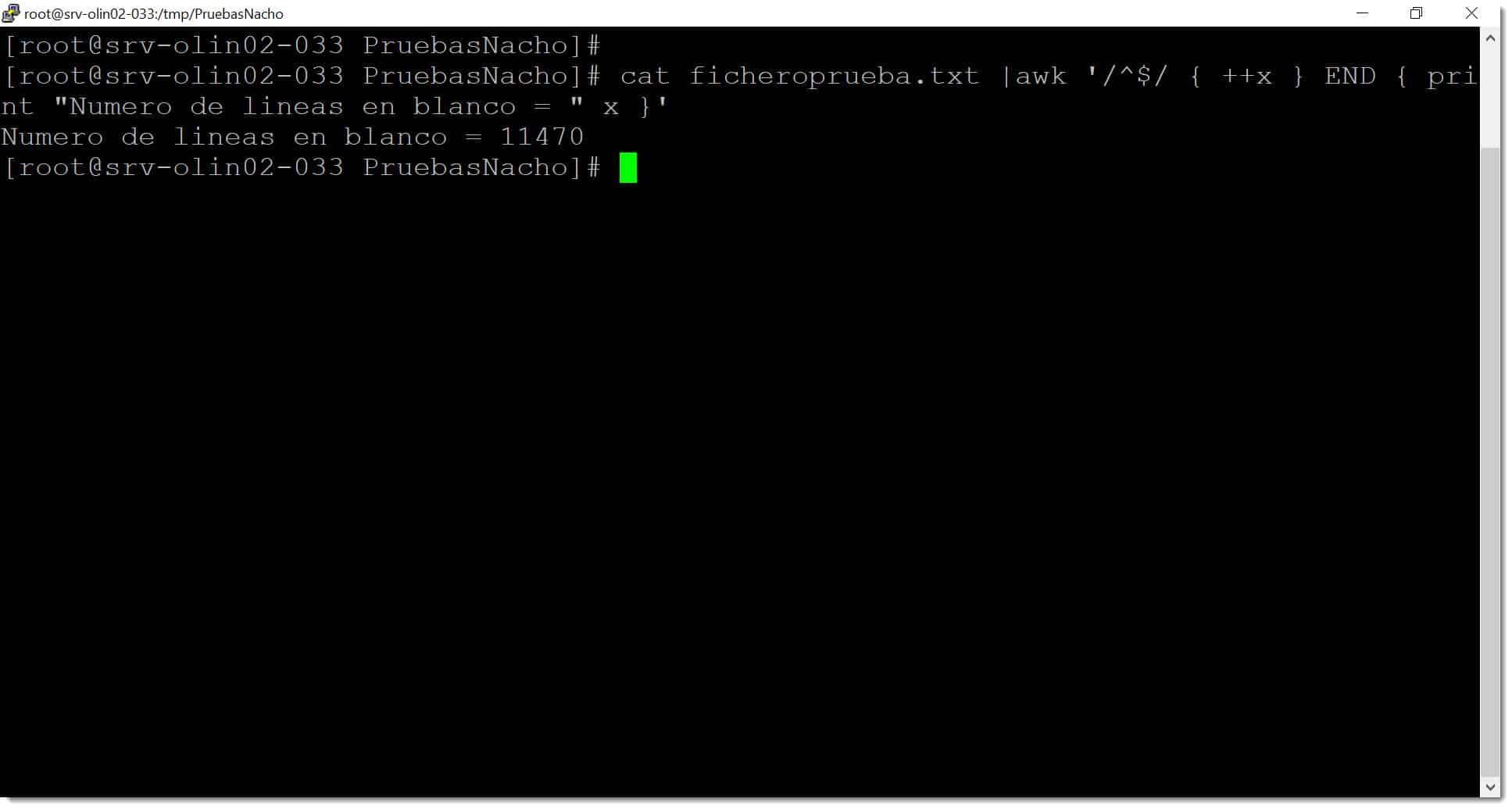
Imagen. Ejecución del oneline para contar líneas en blanco mediante script Linux
Con esto ya tendríamos claro el número de líneas en blanco, que lo podríamos confrontar con el número total de líneas para saber que porcentaje del fichero está poblado y que porcentaje no, para extraer diversas conclusiones y poder tratarlo de múltiples formas.
Una de las formas en que podríamos tratarlo es limpiando las líneas en blanco mediante el uso de AWK, así seguimos usando la misma herramienta que antes y no introducimos complejidad adicional.
La forma de usar este comando es muy sencilla, a la par que “ingeniosa”; y es usando el reenvío de aquellas líneas que contengan algún contenido, purgando aquellas que no tengan contenido, usando para ello el modificador “NF”.
Esto se usaría de la siguiente manera:
# awk ‘NF’ <fichero_origen> > <fichero_destino>
Donde:
Un ejemplo de esto sería:
# awk ‘NF’ ficheroprueba.txt > ficherosalida.txt
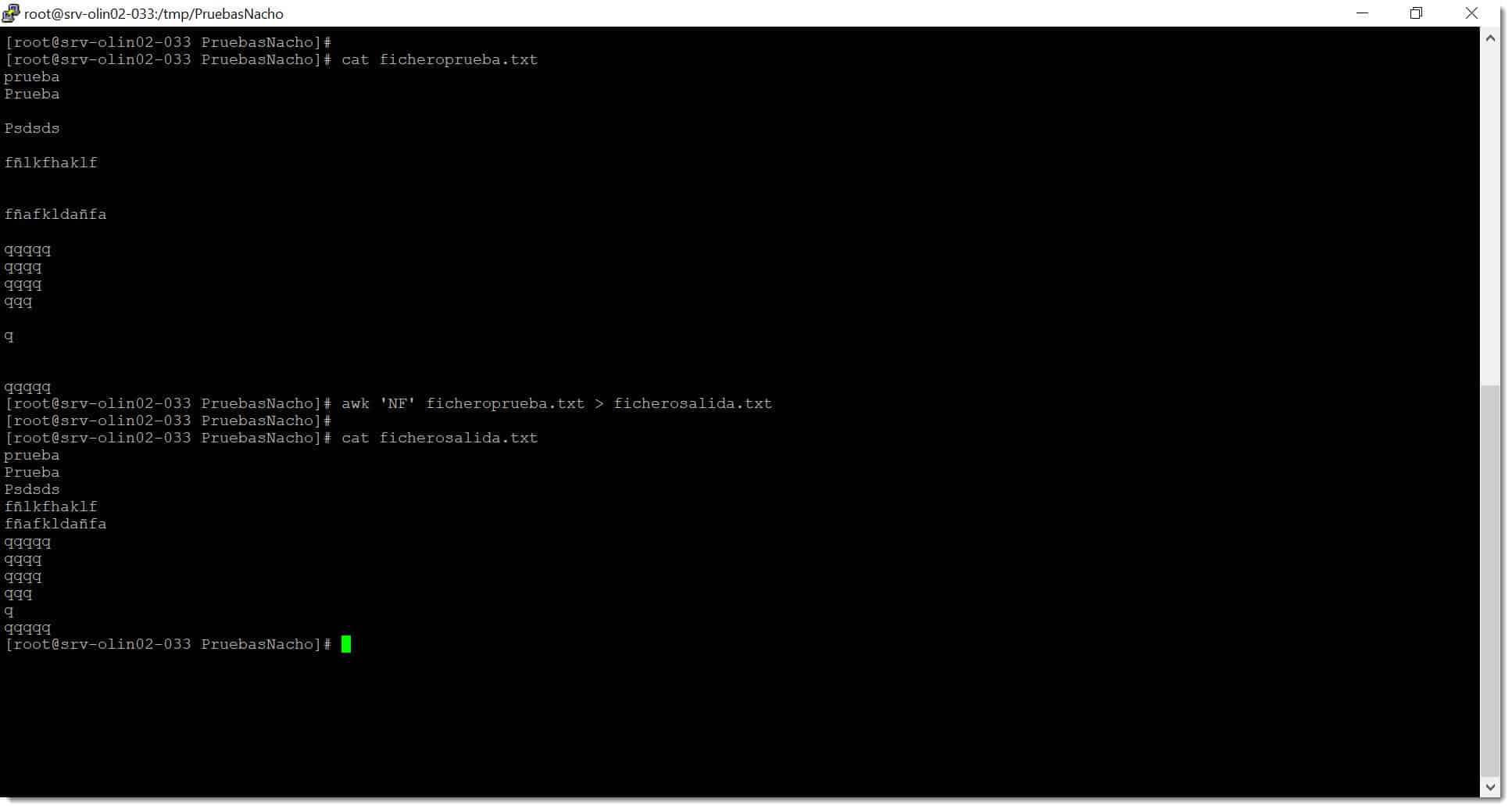
Imagen. Ejecutamos la limpieza de líneas en blanco dentro de un fichero mediante script Linux AWK
Si queremos buscar más opciones, podríamos usar también el comando SED que es otro de los viejos conocidos de administradores de GNU/Linux y UNIX.
En este caso se puede ejecutar el siguiente comando:
# sed ‘/^$/d’ <fichero_origen> > <fichero_destino>
Donde:
Siendo un ejemplo:
# sed ‘/^$/d’ ficheroprueba.txt > ficherocambiado.txt
Como curiosidad, si retiráramos el reenvío a otro archivo, lo que sucedería es que se mostraría el fichero sin los espacios en blanco, pero el fichero seguiría intacto.
Para ello deberíamos lanzar el siguiente comando:
# sed ‘/^$/d’ <fichero_origen>
Siendo el ejemplo:
# sed ‘/^$/d’ ficheroprueba.txt
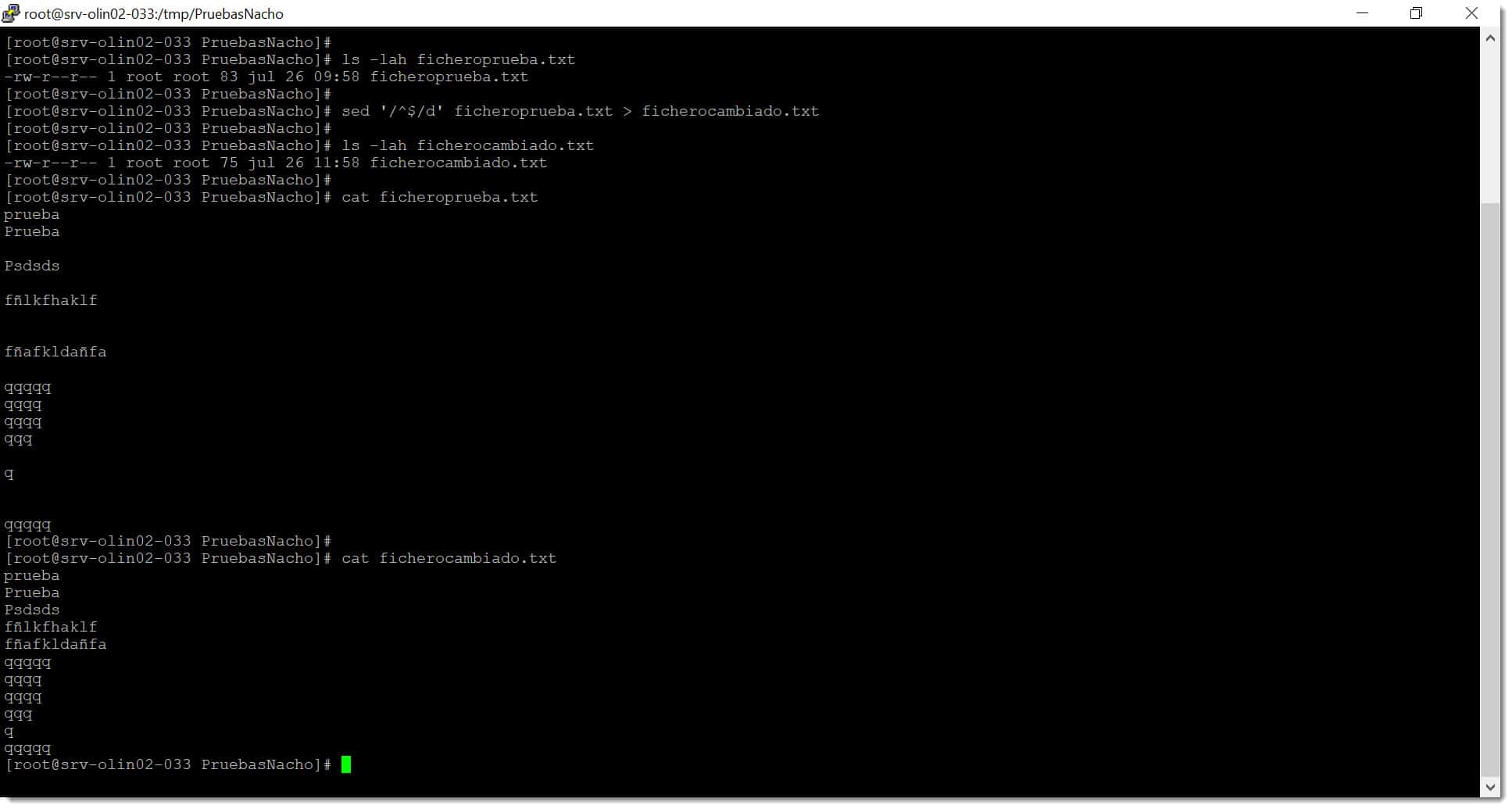
Imagen. Ejecutamos la limpieza de líneas en blanco dentro de un fichero mediante script Linux SED
Y con esto ya podemos decir que hemos repasado este tema más o menos en profundidad.
Como puedes ver en el artículo cómo eliminar líneas en blanco mediante un script GNU/Linux, con un par de comandos enlazados y reconducidos se puede obtener el número de líneas en blanco que se tiene en un fichero, que puede ser una información muy útil cuando operamos con ficheros de configuración.
La ejecución es sencilla y debería estar soportada por todos los sistemas GNU/Linux ya que se realiza mediante AWK, una herramienta ampliamente difundida dentro de los sistemas GNU/Linux y UNIX, pero si encontraras algún problema en su ejecución puedes contactar con nosotros para que intentemos echarte una mano.
Asimismo, recuerda que tienes nuestros tutoriales disponibles para tu consulta en el blog de Jotelulu.
¡Gracias por leernos!