Continue a ler se quiser saber como fazer a recolha de dados básicos para Migrações de GNU/Linux e garantir o sucesso na migração dos seus servidores para a Jotelulu.
Ter informação detalhada da máquina antes da migração deve ser uma garantia de que o processo será realizado sem problemas e que a máquina ficará operacional no novo ambiente.
O primeiro passo é definir a informação a recolher do sistema de origem. Neste caso, os dados mais importantes devem ser os seguintes:
- Nome do equipamento.
- Endereço IP e máscara.
- Número de cores.
- Tamanho da memória RAM.
- Número e tamanho dos discos.
Tendo clara a informação a recolher, deve-se escolher a melhor ferramenta para listar esses dados do sistema. Sendo um sistema GNU/Linux, a melhor opção será a Shell do sistema.
Pré-requisitos ou pré-configuração
Para completar este tutorial e fazer a recolha de dados básicos para Migrações de GNU/Linux, precisará de:
- Ter um registo ativo na Plataforma Jotelulu e aceder com o seu nome e palavra-passe através do processo de login.
- Ter uma subscrição de Servidores.
Como fazer a recolha de dados básicos para Migrações de GNU/Linux
Para recolher a informação, podemos usar várias opções, mas neste caso propomos um script simples, que pode ser executado conforme descrito abaixo.
O script proposto é o seguinte:
#!/bin/bash
Data=$(date +»%Y-%m-%d»)
Hora=$(date +»%H:%M:%S»)
ServerName=$(hostname)
CPUCores=$( lscpu | grep ‘^CPU(s):’ | awk ‘{print $2}’)
RAM=$( lshw -C memory | awk ‘/size:/ {sum+=$2} END {print sum, «GB»}’)
DiskInfo=$(lsblk -dn -o NAME,SIZE)
NetworkInfo=$(ip -4 addr show | awk ‘/inet / {split($2, ip, «/»); print $NF, ip[1], ip[2]}’)
echo «########################################################»
echo «#### Breve Recolha de Dados do Servidor ####»
echo «########################################################»
echo «»
echo «Informação extraída no dia $Data às $Hora»
echo «»
echo «Nome do Servidor:»
echo «——————–»
echo «$ServerName»
echo «»
echo «Endereços IP e Máscaras de Rede:»
echo «———————————»
echo «$NetworkInfo»
echo «»
echo «Número de Cores:»
echo «—————-»
echo «$CPUCores»
echo «»
echo «Tamanho da Memória RAM:»
echo «————————–»
echo «${RAM}GB»
echo «»
echo «Número e Tamanho dos Discos:»
echo «—————————»
echo «$DiskInfo»
echo «»
NOTA: No próximo tópico, veremos como criar e executar o script. Se quiser aprender o que cada comando faz para reutilizá-lo ou adaptá-lo às suas necessidades, consulte a terceira secção deste tutorial.
Como executar o script
Para executar o script, deve criar um ficheiro com extensão “.sh” que é usada para scripts da Shell em GNU/Linux.
Para criar o ficheiro onde introduziremos o código, temos várias opções:
- Criar o ficheiro com o comando “touch”.
- Criar o ficheiro com um editor de texto como Vi, e,Macs, Nano, etc.
Neste caso, vamos criá-lo com o comando “touch”, que pode ser usado para diversas finalidades, como atualizar a data e hora de acesso a um ficheiro ou, como neste caso, criar um novo ficheiro.
O modo de uso é muito simples:
# touch <Nome_Ficheiro.extension>
Como queremos chamar o ficheiro «DadosServidor.sh», executaremos o seguinte comando:
# touch DadosServidor.sh
Depois, podemos confirmar que o ficheiro foi criado listando-o:
# ls -lah DadosServidor.sh
Agora, devemos conceder permissões de execução ao script. Caso contrário, ele não poderá ser executado. Para isso, usamos o comando “chmod”, que permite alterar permissões de ficheiros. Como neste caso queremos permitir a execução, que é a permissão «x», pelo que se adicionará um «+x», e como é indiferente quem o executa, vamos dar permissão a todos os utilizadores, pelo que devermos escrever:
# chmod +x DadosServidor.sh
Agora, podemos editar o ficheiro. Para isso devemos selecionar o editor a usar, que dependerá da preferência de cada utilizador. Neste caso, vamos usar “Vi” pela sua potência e simplicidade.
Para isso, deve-se lançar o comando de chamada para o editor, seguido do nome do ficheiro:
# vi DadosServidor.sh
Depois, pressione a tecla «i» para entrar no modo de inserção, copie e cole o script acima, e depois guarde as alterações pressionando «ESC» (Escape), seguido de «:wq» (sem aspas) para gravar (write) e sair (quit).
Agora já pode executar o script. Para isso, escreva o nome do ficheiro que contém o script, precedido por ./ que indica que se execute o ficheiro:
# ./DadosServidor.sh
Uma boa prática é enviar a saída do script para um ficheiro de registo, armazenando os dados recolhidos:
# ./DadosServidor.sh >> DadosServidor.tx
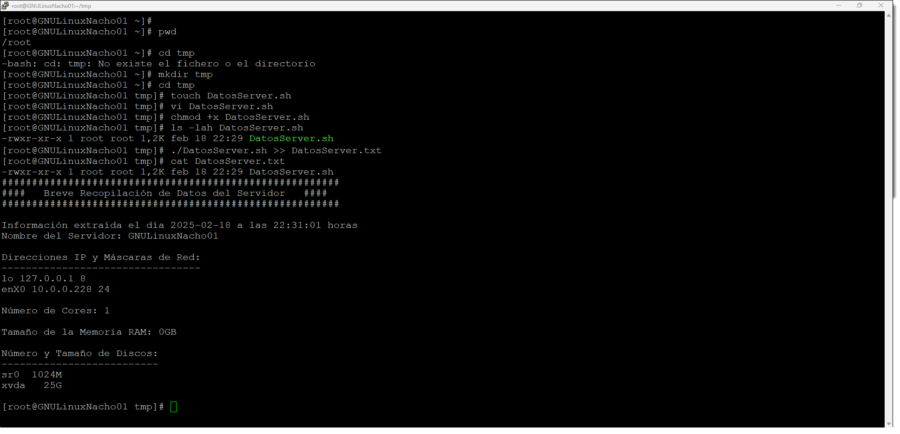
Execução do script de recolha de informação em GNULinux
Breve explicação do script
Agora vamos analisar o script, explicando cada parte para compreender o seu funcionamento e fazer alterações conforme necessário para que se adapte melhor às nossas necessidades.
O script começa com a linha em que se declara que se vai executar um script usando a linha de comandos, que é o que se denomina normalmente como «shebang».
#!/bin/bash
Onde:
- #! : É o próprio “shebang” que indica que se use a Shell para executar.
- /bin/bash : É a Shell com que se executa, que nesta caso será a BASH ou Bourne Again Shell, que é a Shell mais comum em distribuições GNU/Linux.
A seguir, obtemos a data e hora do sistema, pelo que se usam as seguintes linhas de script:
Data=$(date +»%Y-%m-%d»)
Hora=$(date +»%H:%M:%S»)
Onde:
- Data=$(): Usa-se para declarar a variável onde será guardada a saída do comando situada após o símbolo de igual. Neste caso, para recolher a data do momento da execução.
- Hora= $(): Usa-se para declarar a variável onde será guardada a saída do comando situada após o símbolo de igual. Neste caso, para recolher o dia do momento da execução.
- Date: É o comando que permite mostrar a data e a hora do sistema no momento da execução.
- +»%Y-%m-%d»: Recolhe-se a informação da data no formato “Ano-Mês-Dia”.
- +»%H:%M:%S»: Recolhe-se a informação da hora no formato “Hora:Minutos:Segundos”.
O ponto seguinte é a recolha do nome do servidor:
ServerName=$(hostname)
Onde:
- ServerName=$(): Usa-se para declarar a variável onde se guardará a saída do comando.
- Hostname: Comando usado para consultar o nome da máquina.
O próximo ponto é extrair o número de cores da máquina:
CPUCores=$( lscpu | grep ‘^CPU(s):’ | awk ‘{print $2}’)
Onde:
- CPUCores=$(): Usa-se para declarar a variável onde será guardada a saída do comando.
- lscpu: Serve para mostrar o número de processadores e núcleos do sistema.
- |: Usa-se para canalizar a saída de um comando para o seguinte, o que é comumente chamado de pipeline ou tubagem.
- grep ‘^CPU(s):‘ : Usa-se o comando de busca de cadeias de texto “grep” para procurar a linha que começa por “CPU”.
- awk ‘{print $2}’: Usa-se a linguagem de tratamento de texto AWK para mostrar apenas a segunda coluna, que neste caso é o número de cores.
O próximo ponto é consultar a RAM ou memória principal do sistema:
RAM=$( lshw -C memory | awk ‘/size:/ {sum+=$2} END {print sum, «GB»}’)
Onde:
- RAM=$(): Usa-se para declarar a variável onde será guardada a saída do comando.
- lshw -C memory: O comando “lshw” é usado para mostrar informações do hardware (list hardware), neste caso, da memória.
- | : Usa-se para canalizar a saída de um comando para o seguinte, o que é comumente chamado de pipeline ou tubagem.
- awk ‘/size:/ {sum+=$2} END {print sum, «GB»}’: Usa-se AWK para fazer a busca pela cadeia “size”, que apresenta os tamanhos dos módulos de RAM, e somá-los.
O passo seguinte é obter a informação dos discos do sistema:
DiskInfo=$(lsblk -dn -o NAME,SIZE)
Onde:
- DiskInfo=$(): Usa-se para declarar a variável onde será guardada a saída do comando.
- lsblk -dn -o NAME,SIZE: O comando “lsblk” é usado para listar os dispositivos de bloco, como discos ou partições. Neste caso, ao utilizar o modificador -dn, apenas os discos físicos são exibidos de forma limpa. Além disso, o modificador “ – o NAME,SIZE” faz com que sejam mostrados o nome do disco e o seu tamanho em GB.
Finalmente, do lado dos dados do equipamento, falta extrair a informação da rede, o que fazemos com a seguinte linha:
NetworkInfo=$(ip -4 addr show | awk ‘/inet / {split($2, ip, «/»); print $NF, ip[1], ip[2]}’)
Onde:
- NetworkInfo=$(): Usa-se para declarar a variável onde será guardada a saída do comando.
- ip -4 addr show : Comando usado para mostrar as configurações de rede IPv4.
- | : Usa-se para canalizar a saída de um comando para o seguinte, o que é comummente chamado de pipeline ou tubagem.
- awk ‘/inet / {split($2, ip, «/»); print $NF, ip[1], ip[2]}’ : Usamos AWK para procurar a cadeia “inet”, que apenas recolherá os dados de IPv4. Em seguida, extrai a informação da coluna 2, que contém os dados de IP e máscara.
Por outro lado, vamos ver como apresentar informação no ecrã com o comando “echo”. Como há várias linhas deste tipo, vamos analisar uma que mistura variáveis e texto plano.
echo «Informação extraída no dia $Data às $Hora horas»
Onde:
- Echo: É o comando usado em GNU/Linux para exibir um texto no ecrã. Neste caso, se escrevermos echo “Olá mundo!”, o que será mostrado no ecrã será: Olá mundo!. Se, por outro lado, escrevermos echo “Dia $Data”, o que será exibido será a cadeia “Dia” seguida pela data armazenada previamente na variável $Data, conforme visto acima.
Com isto, já teríamos o script analisado e esperamos que tenha ficado mais ou menos claro.
Conclusão
Tal como vimos no tutorial, saber como fazer a recolha de dados básicos para migrações de GNU/Linux é relativamente simples com o script que propomos. Ele está perfeitamente montado para que possa ser copiado diretamente para a consola de GNU/Linux através da shell, embora recomendemos sempre executá-lo a partir de um ficheiro de script gerado especificamente para esta operação.
Além disso, é possível realizar várias consultas sobre a configuração básica dos dispositivos em sistemas GNU/Linux com pequenas variações em relação ao que propusemos.
Esperamos que seja útil.
Obrigado por nos ler!






