






Fique connosco ao longo deste artigo onde iremos discutir as 10 principais preocupações ao configurar o Disaster Recovery numa PME.
Planear, configurar e manter um plano de recuperação de desastres verdadeiramente funcional e eficaz requer um planeamento cuidadoso e uma gestão de vários fatores.
O esforço investido na preparação de planos de contingência, na implementação de infraestruturas, processos e operações alternativas, bem como na sensibilização e formação do pessoal antes da ocorrência do incidente são elementos fundamentais para garantir a recuperação das operações da empresa de forma rápida e eficiente após um incidente.
Um investimento adequado numa solução de Disaster Recovery (DR) devidamente concebida e executada não só protegerá os ativos críticos da organização, como também garantirá a continuidade do negócio e a resiliência contra contingências futuras.
NOTA: quanto às normas, estes procedimentos, operações e planos estão incluídos na ISO/UNE/22.301 “Sistemas de Gestão da Continuidade de Negócio”.
Vamos enumerar as preocupações ao configurar uma recuperação de desastres:
Como somos megafãs de listas, decidimos apresentar este artigo sobre preocupações e desafios como uma lista das 10 principais preocupações que todas as pequenas empresas têm quando enfrentam o desafio de configurar um DR.
- Alinhamento dentro da empresa.
- Avaliação de riscos e análise de impacto.
- Custo da solução e falta de orçamento.
- Dependências e coordenação.
- Definição de objetivos da recuperação.
- Procedimentos, documentação e normas.
- Tecnologias usadas versus tecnologias apropriadas.
- Formação e sensibilização.
- Testes, operações e validação.
- Melhoria contínua do Disaster Recovery.
Como sempre, a seguir vamos analisar cada uma delas com alguma profundidade.
Alinhamento dentro da empresa:
Não vamos desenvolver muito este ponto, porque é algo muito simples de entender e muito fácil de implementar se planearmos com um mínimo de reflexão. A primeira coisa que devemos compreender quando propomos um plano de DR é que nós, enquanto departamento de TI, não somos o umbigo do mundo nem o núcleo da empresa, mas sim um departamento que possibilita o correto funcionamento da mesma (pelo menos na maioria das empresas).
Por isso, devemos reunir-nos com os restantes departamentos e administração para definir o que é mais importante, o que não pode ser parado em nenhum momento e o que tem prioridade na recuperação do negócio.
Avaliação de riscos e análise de impacto:
A avaliação de riscos é um dos pontos fundamentais para proteger a nossa organização. Consiste, valha a redundância, em identificar os riscos específicos que podem impactar a nossa organização para desenvolver estratégias para a sua gestão. Dentro disto, podemos encontrar coisas tão diversas como falhas de hardware ou software, erros humanos, atos intencionais de pessoas internas, desastres naturais e até os famosos ataques cibernéticos.
Abordamos este tema no artigo “Como avaliar riscos e ameaças nas PME“, portanto não vamos falar disso neste artigo, deixando ao leitor a opção de aprofundar o conhecimento.
Para além do modelo de avaliação de riscos, existe a Análise de Impacto no Negócio (BIA), que é responsável por determinar como os diferentes tipos de desastres afetam a organização, avaliando o impacto financeiro, operacional e reputacional associado a cada um dos riscos previamente identificados.
Custo da solução e falta de orçamento:
Em todos os projetos, o custo das soluções é um dos pontos mais sensíveis, pois é uma condição normalmente estrita que tornará mais fácil ou mais difícil o desenvolvimento de um projeto. A solução mais completa costuma ser a mais cara… Neste sentido, um projeto de recuperação de desastres não foge a esta regra: geralmente, as soluções são caras, o que pode significar uma barreira intransponível.
Dentro do custo da solução devem ser tidos em conta vários conceitos, como o custo de implementação, ou custo inicial, e o custo de manutenção da solução, bem como alguns indicadores que nos ajudarão a determinar o equilíbrio entre o custo de implementação e o benefício que a solução gera.
No custo inicial devemos ter em conta tanto o custo do pessoal envolvido (horas de trabalho, contratação de consultores, etc.) como os custos associados à infraestrutura, como os servidores e outro hardware, os custos de licenças, custos de subscrição de serviços e fornecedores de serviços cloud, etc.
Além disso, será necessário ter em conta o que custa manter uma posição de segurança ativa e vigilante. Logicamente, este custo é superior ao custo de não fazer nada, mas pode acabar por ser um preço muito reduzido a pagar se evita ou minimiza o impacto de uma situação catastrófica para o negócio.
Sobre este tema, recomendamos a leitura do artigo “Qual é o custo real de não investir em segurança?” no nosso blog.
Dependências e coordenação:
Os sistemas e processos não são entidades independentes que flutuam no ar. Existem inúmeras interdependências entre todos os elementos que compõem a nossa organização.
Para criar um plano de DR funcional, estas interdependências entre os diferentes sistemas devem ser revistas para que sejam corretamente identificadas e documentadas, para garantir que a recuperação dos processos de negócio é eficiente e coordenada.
Outro ponto a ter em conta é a relação com os parceiros de negócio e fornecedores, para que possamos garantir que todos os stakeholders críticos para a organização participam nos nossos planos de DR ou têm outros planos compatíveis com os nossos e que possam ser coordenados caso ocorra algum incidente.
Estes planos devem ser revistos e praticados com maior ou menor frequência para garantir que não se mantêm apenas no quadro teórico.
Por outro lado, e acima de tudo, deve existir uma integração clara com a direção da empresa e um apoio claro por parte desta, pois sem este apoio é possível que as coisas não funcionem.
Definição de objetivos da recuperação:
Quem tem alguma experiência em gestão de projetos de TI sabe, seja por experiência própria ou por ter aprendido num curso, que a maioria dos projetos de TI sofre algum tipo de problema ao longo da sua execução. Na verdade, os estudos dizem que apenas cerca de 20% são executados de forma totalmente satisfatória.
Quem já estudou metodologias como o PMP, ACP ou mesmo Scrum saberá que na maioria dos casos tal se deve à gestão incorreta dos requisitos e definição dos objetivos do projeto, por isso, no caso de estabelecer um plano de recuperação de desastres (DR), devemos ter muito claros os objetivos antes de iniciar o projeto. São a pedra basilar.
Os objetivos de recuperação que devemos estabelecer devem basear-se no conhecimento dos recursos e serviços da nossa organização, bem como no conhecimento das ligações e dependências que estas possam ter, e serão principalmente duas:
- Objetivo de Tempo de Recuperação (RTO).
- Objetivo de Ponto de Recuperação (RPO).
A título de breve introdução, diremos que o “Recovery Time Objective (RTO)” estabelece o tempo máximo em que os processos críticos da organização devem ser restaurados após a ocorrência de um incidente. Já o “Recovery Point Objective (RPO)” estabelece a quantidade máxima de dados que podem ser perdidos desde o último backup, sendo medido em tempo.
NOTA: pode obter mais informações sobre este tema no artigo “Disaster Recovery: o que significam as siglas RPO, RTO, WRT ou MTD e porque é que são importantes?” no nosso blog.
Procedimentos, documentação e normas:
No âmbito da filosofia de gestão de serviços, costuma dizer-se que existem três pontos-chave que fazem com que tudo funcione quando aplicados corretamente: falamos da tríade “Pessoas, Processos e Tecnologia”, que são os constituintes de uma estratégia adequada de gestão do conhecimento. Dentro desta gestão do conhecimento, neste caso, vamos focar-nos nos processos que permitem à nossa equipa saber o que deve ser feito em cada momento, algo que em casos como o DR é de extrema importância.
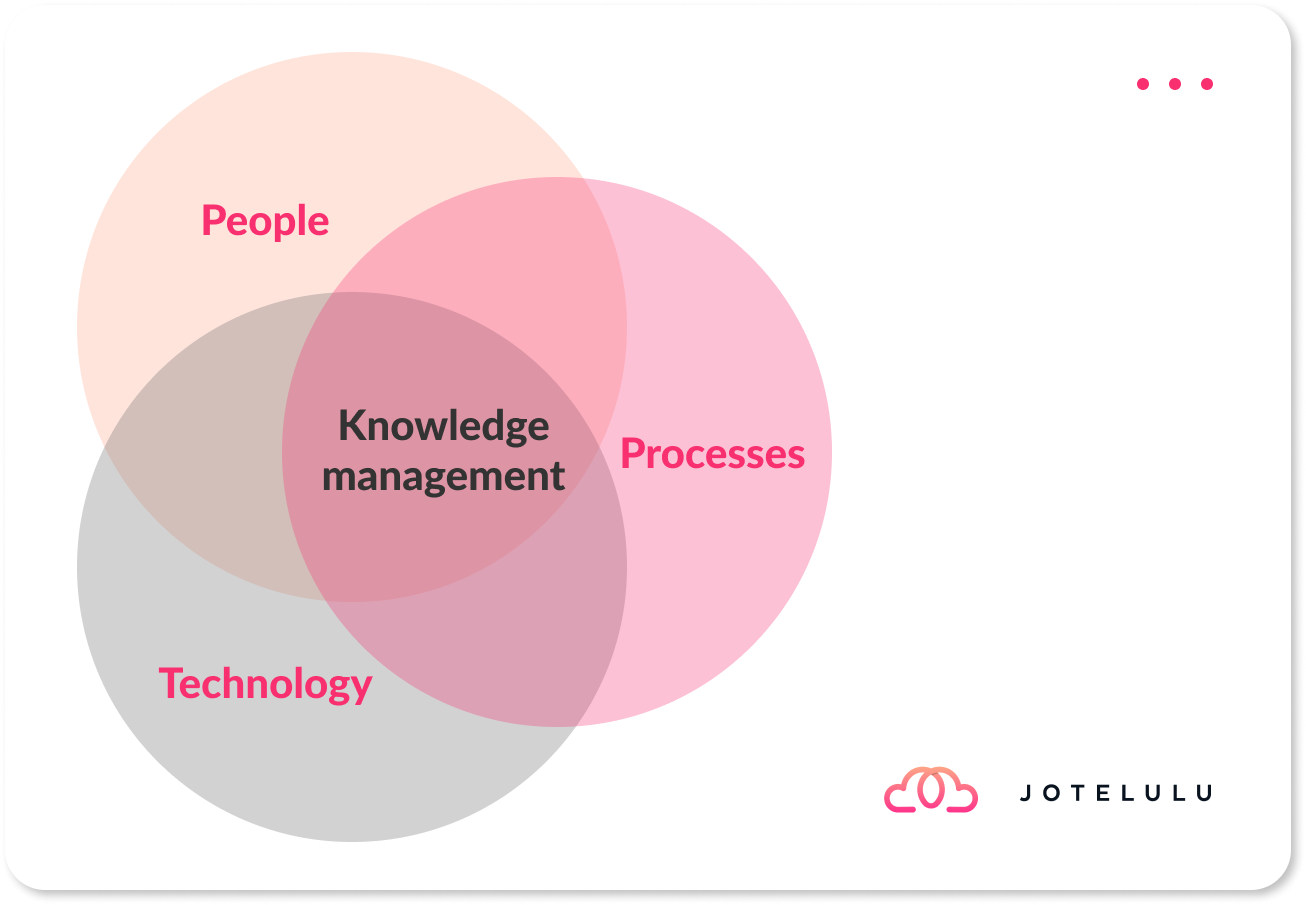
Para começar, é necessário definir procedimentos claros, que não deixem margem para dúvidas ou para erros, e que ajudem o pessoal, numa situação tão stressante como uma quebra de serviço, a conseguir trabalhar corretamente. Aqui incluem-se todos os tipos de procedimentos, como cadeias de comunicação e notificação, procedimentos de restauro, soluções alternativas, etc.
Os procedimentos podem ser de vários tipos, mas no caso de um Disaster Recovery costuma ser muito útil utilizar guias passo a passo com checklists que podem ser de dois tipos: a primeira checklist serve para classificar o tipo de medida a realizar com base no evento que gerou o incidente; o segundo tipo é a verificação clássica realizada após a execução do procedimento.
Além disso, deve existir documentação detalhada sobre todos os aspetos que envolvem o plano de DR, incluindo planos de cópias de segurança e recuperação, procedimentos de escalamento, configurações de hardware e software dos sistemas originais e das cópias de segurança, assim como as funções envolvidas na recuperação de desastres e as suas responsabilidades. É também fundamental contar com documentos que providenciem cobertura legal e de conformidade, no âmbito das recuperações de desastre, como a ISO 27.001, ISO 22.301, Cobit, etc.
Estes últimos são documentos de conformidade regulamentar que devem ser criados para cumprir os regulamentos e normas da indústria que se aplicam no território onde a organização opera.
Um dos requisitos regulamentares é relativo à segurança dos dados pessoais, que têm de ser sempre salvaguardados, garantido a sua encriptação e cópia, tanto em trânsito como no local onde são armazenados, e que foram implementados controlos de acesso adequados para os proteger contra possíveis ataques ou fugas.
Tecnologias utilizadas versus tecnologias apropriadas:
As tecnologias utilizadas são determinantes em casos de recuperação de desastres; as diferentes ferramentas e tecnologias devem ser avaliadas em função do orçamento, das diferentes legislações e normas que se aplicam à empresa, etc.
Por um lado, a primeira coisa que devemos considerar é o modelo que queremos utilizar para a infraestrutura de backup e replicação. Devemos selecionar tecnologias de armazenamento e replicação que nos permitam fazer backups de forma eficiente e recuperar dados de forma rápida.
Outro ponto que a avaliar é a automatização: é importante realizar a implementação de ferramentas de automatização que (dentro do nosso orçamento) nos permitam melhorar a eficiência e reduzir os erros, que serão geralmente de natureza humana.
Por último, e embora o leitor possa assumir qual é a nossa aposta na Jotelulu, a última decisão tecnológica que devemos ter em conta é se queremos utilizar soluções on-premise ou baseadas na cloud. É claro que não podemos escolher apenas soluções de recuperação exclusivamente locais ou exclusivamente na cloud. Devemos pensar em soluções híbridas que nos proporcionem um bom equilíbrio entre disponibilidade e custo. Este último fator, bem como a velocidade de recuperação e principalmente a segurança, devem ser sempre tidos em conta.
Formação e sensibilização:
Antes, fizemos referência ao conceito “Pessoas, Processos e Tecnologias”, e aqui é novamente referido; é tão importante que afeta três dos pontos discutidos neste resumo das preocupações com o DR.
Neste sentido, é mais um daqueles pontos com os quais somos um bocado chatos. Deve haver formação e treino do pessoal técnico que deve aplicar os processos de DR para que desta forma não sejam meros autómatos a executar um procedimento de DR, mas sim pessoas que compreendem os papéis e as responsabilidades que devem exercer em caso de desastre.
Por outro lado, para todo o pessoal sem exceção, quer seja técnico ou não, deve ser estabelecida uma política de consciencialização que se concentre na promoção de uma cultura de sensibilização para a importância da recuperação de catástrofes e da continuidade do negócio.
Testes, operações e validação:
Tudo o que se faz no contexto de um plano elaborado deve conter uma série de testes e operações que visam a validação, pelo que devem ser estabelecidos vários elementos para controlar se tudo está perfeitamente planeado, criado e mantido.
Os testes regulares do plano de DR, bem como de cada uma das suas partes, devem ser estabelecidos de forma recorrente para garantir que tudo está a funcionar como planeado e que todos os colaboradores sabem como desempenhar o seu papel corretamente. Devem ser realizados testes completos sempre que possível, mas dada a sua complexidade, podemos dividir alguns dos processos que a equipa realiza continuamente para agilizar a execução. O plano de testes deve incluir simulações de desastres e testes de restauro de dados.
Por outro lado, devemos verificar se os procedimentos de recuperação cumprem os objetivos de RTO e RPO estabelecidos no planeamento, sendo definido também um plano de documentação e correção para qualquer falha ou ineficiência detetada durante os testes.
Finalmente, devem ser implementados sistemas de monitorização para detetar falhas ou problemas na infraestrutura de DR, para garantir que são reportados e resolvidos rapidamente.
Melhoria contínua do Disaster Recovery:
Como em quase todos os artigos em que falamos de sistemas ou de segurança, temos de referir este ponto. A obrigação de cada administrador, de cada técnico e de cada responsável por um serviço é fazer com que as coisas melhorem a cada dia. “Quem não evolui, extingue-se”, e esta é uma máxima aplicável até aos dinossauros, que viveram num mundo muito menos mutável. Agora imagine o quanto é válido para nós.
Devem ser constantemente avaliados os novos riscos, devemos retirar lições de tudo e propor melhorias continuamente, para alterar sistemas, atualizá-los, etc.
Sem dúvida, devemos viver numa retrospetiva contínua, na qual nos interrogamos: o que está bem feito? O que pode ser melhorado? O que precisa de mudar? E a partir daí, trabalhar em planos de melhoria.
Afinal de contas, isto não é mais que trabalhar num modelo baseado no Ciclo de Deming em que estaremos sempre numa das famosas fases:
- Plan.
- Do.
- Check.
- Act.
Conclusões:
Como vimos neste artigo, as 10 principais preocupações na hora de fazer um Disaster Recovery numa PME são simples de compreender e são partilhadas por quase toda a gente, uma vez que estamos a arriscar a sobrevivência dos nossos negócios. É importante ter em conta que são mais fáceis de gerir se conseguirmos elaborar um bom plano de implementação e manutenção. Devemos realçar que precisamos do apoio da direção e de planear e investir tempo para pensar seriamente nas necessidades, no plano de implementação, etc. para, assim, estarmos preparados quando surgem os problemas que tornam necessário o funcionamento do plano.
Se quiser saber mais sobre segurança, recomendamos que dê uma vista de olhos a estes outros artigos do nosso blog.
- Etapas para gerir um incidente de segurança da informação nas TI
- Qual é o custo real de não investir em segurança?
- Problemas mais comuns com os backups
- Estratégia de backup 3,2,1
- As 5 principais causas de perda de dados nas PME
- Como avaliar riscos e ameaças nas PME
- Porque é que o Disaster Recovery é tão complexo?
Ou visite a nossa secção de tutoriais, onde pode encontrar conteúdo como este:
- Como ativar o Disaster Recovery da Jotelulu
- Como configurar a política de replicação no Disaster Recovery da Jotelulu
Obrigado por ler até aqui!








